Uma forma de lidar com grandes conjuntos de dados e identificar informações relevantes é agrupar estes dados. O agrupamento é feito em tabelas, denominadas de distribuições de frequências. A construção de distribuição de frequências é geralmente realizada de forma distinta para variáveis discretas (distribuição por pontos) e contínuas (distribuição por classes ou intervalos).
Neste exemplo, vamos utilizar os dados coletados do comprimento, diâmetro e cor de grão de café.
library(tidyverse)library(rio)library(metan)url <-"https://raw.githubusercontent.com/TiagoOlivoto/classes/refs/heads/master/FIT5306/data/cafe.csv"df <- rio::import(url)# mostrar os dadosknitr::kable(df)
amostra
comp_grao
diam_grao
cor_grao
1
15.89
11.66
vermelho
2
14.68
11.37
vermelho
3
13.60
11.39
vermelho
4
11.39
11.58
vermelho
5
14.27
10.69
vermelho
6
15.02
11.28
vermelho
7
11.88
8.54
vermelho
8
15.06
10.99
amarelo
9
15.98
11.42
amarelo
10
13.32
9.38
amarelo
11
14.64
11.04
amarelo
12
12.15
9.30
amarelo
13
15.59
11.99
amarelo
14
14.26
10.47
verde
15
12.04
8.70
verde
16
10.95
8.43
verde
17
12.88
9.36
verde
18
11.86
9.10
verde
19
14.02
9.17
verde
20
11.99
10.20
verde
21
12.77
9.88
verde
22
12.47
8.53
verde
23
9.75
6.63
verde
24
9.09
7.29
verde
25
10.47
8.54
verde
26
10.14
8.32
verde
27
11.48
8.43
verde
28
12.66
9.25
verde
Variáveis qualitativas e quantitativas discretas
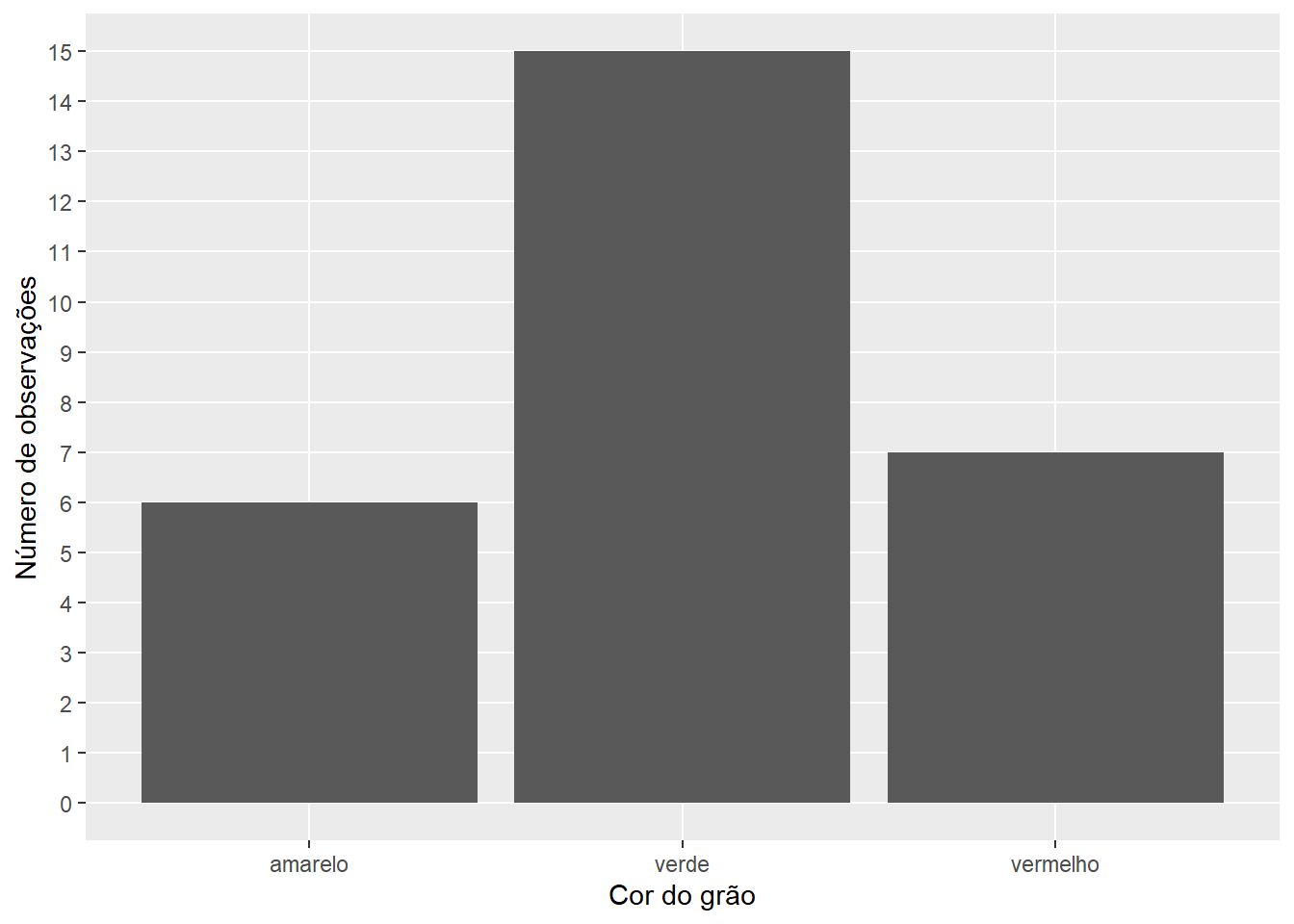
Para exemplificar a construção de tabelas de frequências de variáveis qualitativas / quantitativas discretas, utilizaremos a variável cor do grão. Neste caso, três classes (classes naturais) estão presentes: vermelho, amarelo e verde. Assim, a construção da tabela de frequência diz respeito a contagem de observações em cada uma destas classes e o cálculo das frequências relativas e absolutas.
Representação tabular
Pode-se criar facilmente esta tabela de frequência combinando as funções count() e mutate() do pacote dplyr (parte do tidyverse).
Para apresentar estes dados graficamente, pode-se construir um gráfico de barras, mostrando a contagem em cada classe.
ggplot(df, aes(cor_grao)) +geom_histogram(stat="count") +scale_y_continuous(breaks =0:15) +labs(x ="Cor do grão",y ="Número de observações") +theme(panel.grid.minor =element_blank())
Warning in geom_histogram(stat = "count"): Ignoring unknown parameters:
`binwidth` and `bins`
Variáveis quantitativas
Para o caso de variáveis quantitativas contínuas (ex. X), precisamos agrupar os valores observados em intervalos de classe. Por exemplo, quando medimos uma altura de uma planta (ex. 1,86 m), a altura real não está limitado a segunda casa decimal. Então, a melhor forma será criar regiões (intervalos), de modo que possamos contemplar um conjunto de valores.
Um critério empírico, para definição do número de classes (\(k\)) a ser criado se baseia no número de elementos (\(n\)) na amostra. Caso (\(n\)) seja igual ou inferior a 100, calcula-se o número de classes com \(k = \sqrt{n}\). Caso (\(n\)) seja maior que 100, calcula-se o número de classes com \(k = 5 log_{10}(n)\).
Após a determinação do número de classes, é necessário determinar a amplitude total (\(A\)), dada por:
\[
A = \max(X) - \min(X)
\]
Posteriormente, determina-se a amplitude da classe (\(c\)), dada por:
\[
c = \frac{A}{k - 1}
\]
Por fim, calcula-se o o limite inferior (\(LI_1\)) e superior (\(LS_1\)) da primeira classe, dados por
\[
LI_1 = min(X) - c/2\\\\
\]
\[
LS_1 = LI_1 + c
\]
O valor do limite superior não pertence a classe e será contabilizado para a próxima classe. Dizemos, então, que o conjunto é fechado a esquerda e aberto à direita. O limite inferior da segunda classe é dado pelo limite superior da primeira class (\(LI_2 = LS_1\)); o limite superior da segunda classe é dado por (\(LS_2 = LI_2 + c\)). Esta lógica segue até completar-se o número de classes do conjunto.
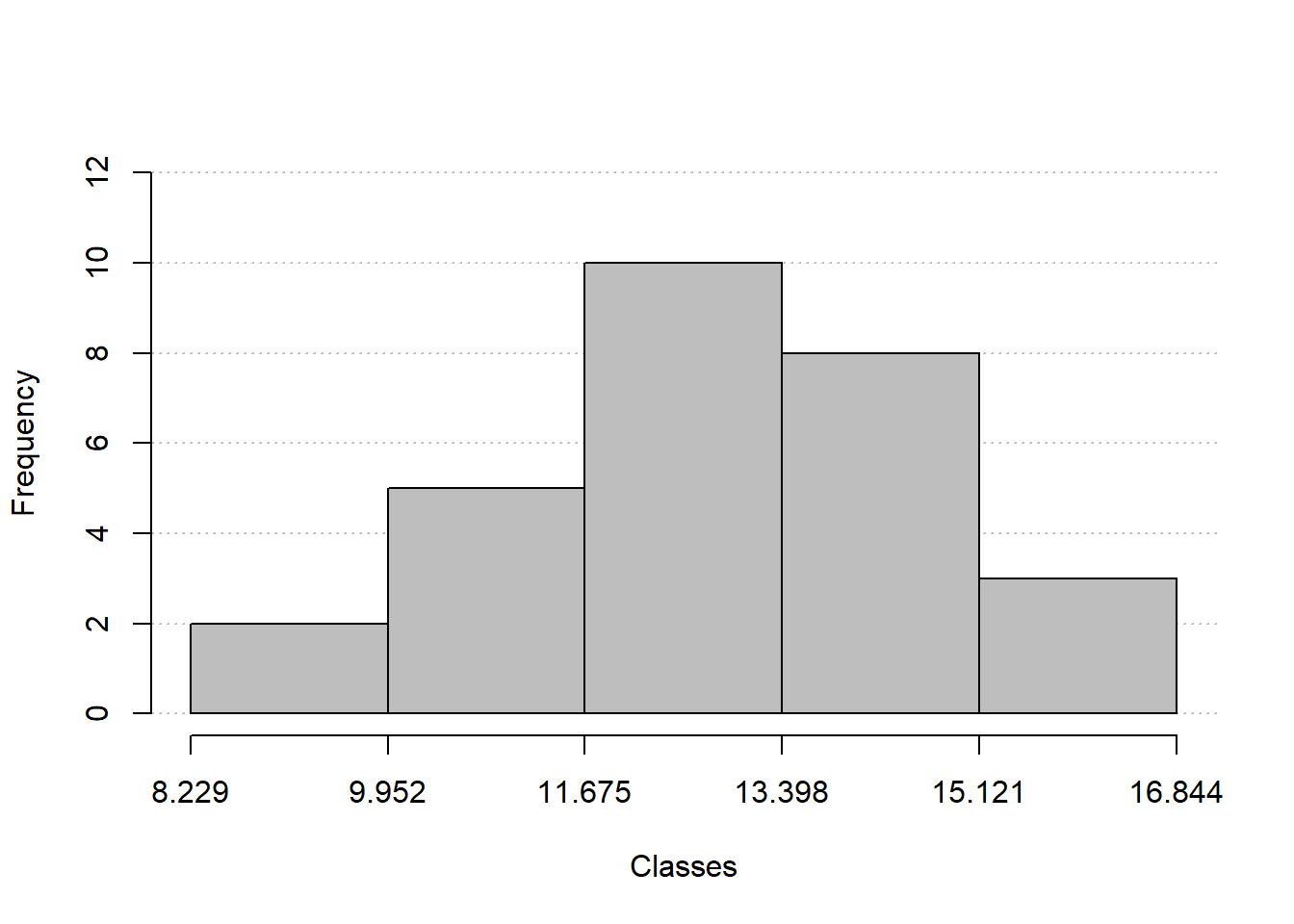
A função freq_table() está disponível no pacote metan e pode ser utilizada para automatizar o processo de construção de tabelas de frequências, tanto para variáveis qualitativas como quantitativas. Basta informar o conjunto de dados, a variável, e, opcionalmente, o número de classes a ser criado.
Apresentação tabular
frequencias <-freq_table(df, comp_grao)
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(where(is.numeric), round, digits = digits)`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))
ℹ The deprecated feature was likely used in the metan package.
Please report the issue at <https://github.com/nepem-ufsc/metan/issues>.
knitr::kable(frequencias$freqs)
class
abs_freq
abs_freq_ac
rel_freq
rel_freq_ac
8.229 |— 9.952
2
2
0.071
0.071
9.952 |— 11.675
5
7
0.179
0.250
11.675 |— 13.398
10
17
0.357
0.607
13.398 |— 15.121
8
25
0.286
0.893
15.121 |—| 16.844
3
28
0.107
1.000
Total
28
28
1.000
1.000
Apresentação gráfica
freq_hist(frequencias)
Tutorial R
Source Code
---title: "2. Distribuição de frequências"---Uma forma de lidar com grandes conjuntos de dados e identificar informações relevantes é agrupar estes dados. O agrupamento é feito em tabelas, denominadas de distribuições de frequências. A construção de distribuição de frequências é geralmente realizada de forma distinta para variáveis discretas (distribuição por pontos) e contínuas (distribuição por classes ou intervalos).Neste exemplo, vamos utilizar os dados coletados do comprimento, diâmetro e cor de grão de café.```{r warning=FALSE, message=FALSE}library(tidyverse)library(rio)library(metan)url <- "https://raw.githubusercontent.com/TiagoOlivoto/classes/refs/heads/master/FIT5306/data/cafe.csv"df <- rio::import(url)# mostrar os dadosknitr::kable(df)```# Variáveis qualitativas e quantitativas discretasPara exemplificar a construção de tabelas de frequências de variáveis qualitativas / quantitativas discretas, utilizaremos a variável cor do grão. Neste caso, três classes (classes naturais) estão presentes: vermelho, amarelo e verde. Assim, a construção da tabela de frequência diz respeito a contagem de observações em cada uma destas classes e o cálculo das frequências relativas e absolutas.## Representação tabularPode-se criar facilmente esta tabela de frequência combinando as funções `count()` e `mutate()` do pacote `dplyr` (parte do `tidyverse`).```{r}tab_feq <- df %>%count(cor_grao) |>mutate(abs_freq = n,abs_freq_ac =cumsum(abs_freq),rel_freq = abs_freq /sum(abs_freq),rel_freq_ac =cumsum(rel_freq))knitr::kable(tab_feq)```## Representação gráficaPara apresentar estes dados graficamente, pode-se construir um gráfico de barras, mostrando a contagem em cada classe.```{r}#| out-width: "100%"ggplot(df, aes(cor_grao)) +geom_histogram(stat="count") +scale_y_continuous(breaks =0:15) +labs(x ="Cor do grão",y ="Número de observações") +theme(panel.grid.minor =element_blank())```# Variáveis quantitativasPara o caso de variáveis quantitativas contínuas (ex. `X`), precisamos agrupar os valores observados em intervalos de classe. Por exemplo, quando medimos uma altura de uma planta (ex. 1,86 m), a altura real não está limitado a segunda casa decimal. Então, a melhor forma será criar regiões (intervalos), de modo que possamos contemplar um conjunto de valores.Um critério empírico, para definição do número de classes ($k$) a ser criado se baseia no número de elementos ($n$) na amostra. Caso ($n$) seja igual ou inferior a 100, calcula-se o número de classes com $k = \sqrt{n}$. Caso ($n$) seja maior que 100, calcula-se o número de classes com $k = 5 log_{10}(n)$.Após a determinação do número de classes, é necessário determinar a amplitude total ($A$), dada por:$$A = \max(X) - \min(X)$$Posteriormente, determina-se a amplitude da classe ($c$), dada por:$$c = \frac{A}{k - 1}$$Por fim, calcula-se o o limite inferior ($LI_1$) e superior ($LS_1$) da primeira classe, dados por$$LI_1 = min(X) - c/2\\\\$$$$LS_1 = LI_1 + c$$O valor do limite superior não pertence a classe e será contabilizado para a próxima classe. Dizemos, então, que o conjunto é fechado a esquerda e aberto à direita. O limite inferior da segunda classe é dado pelo limite superior da primeira class ($LI_2 = LS_1$); o limite superior da segunda classe é dado por ($LS_2 = LI_2 + c$). Esta lógica segue até completar-se o número de classes do conjunto.A função `freq_table()` está disponível no pacote `metan` e pode ser utilizada para automatizar o processo de construção de tabelas de frequências, tanto para variáveis qualitativas como quantitativas. Basta informar o conjunto de dados, a variável, e, opcionalmente, o número de classes a ser criado.## Apresentação tabular```{r}frequencias <-freq_table(df, comp_grao)knitr::kable(frequencias$freqs)```## Apresentação gráfica```{r}#| out-width: "100%"freq_hist(frequencias)```# Tutorial R```{=html}<div class="video-container"><iframe src="https://www.youtube.com/embed/SmaFbcB-OAI" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe></div>```