# meu computador (mudar de acordo)
setwd("D:/Desktop/UFSC/aulas/classes/RGV410046/data")8. Visualização de dados
Diretório
Pacotes
Para reprodução destes exemplos, os seguintes pacotes precisam ser instalados do github
# pacote para download de mapas
remotes::install_github("ropensci/rnaturalearthhires")
remotes::install_github("ricardo-bion/ggradar")Antes de carregar, verifique se os seguintes pacotes estão instalados.
library(tidyverse)
library(metan)
library(rio)
library(ggridges)
library(rnaturalearth)
library(fmsb)
library(lubridate)
library(geobr)
library(esquisse)
library(DataExplorer)
library(patchwork)Dados
Grãos café
Os dados contidos na aba cafe do arquivo examples_data.xlsx serão utilizados. Este arquivo contém dados do comprimento e largura (mm) de grãos de café, amostrados por diferentes grupos de alunos da disciplina de Bioestatística e Experimentação Agrícola e classificados em diferentes cores. Para carregar estes dados, utilizamos o seguinte comando.
df <-
import("examples_data.xlsx",
sheet = "cafe",
setclass = "tbl") |>
as_factor(1:3)
df# A tibble: 47 × 5
grupo individuo cor comprimento largura
<fct> <fct> <fct> <dbl> <dbl>
1 Grupo 1 1 vermelho 13.5 16.6
2 Grupo 1 2 vermelho 11.1 14.2
3 Grupo 1 3 vermelho 13.4 15.9
4 Grupo 1 4 vermelho 9.87 14.1
5 Grupo 1 5 verde 11.6 16.1
6 Grupo 1 6 verde 9.86 13.9
7 Grupo 1 7 verde 9.84 12.4
8 Grupo 1 8 verde 10.7 14.8
9 Grupo 1 9 verde 9.98 13.2
10 Grupo 1 10 verde 10.3 13
# ℹ 37 more rowsDados da estação meteorológica
Os dados contidos em estacao_fazenda.csv contém informações de variáveis climáticas obtidas em sensores automáticos de uma estação meteorológica localizada na Fazenda Experimental da Ressacada (UFSC)
Os dados são em escala horária, do dia 01/01/2022 a 28/11/2022, totalizando 7957 observações. Estes dados serão utilizados ainda neste material, na sessão Section 4.12.
df_estacao <-
import("estacao_fazenda.csv", setclass = "tbl") |>
mutate(dia = dmy(dia),
m = fct_relevel(factor(month(dia)), paste0(1:12)),
tmed = (tmax + tmin) / 2) # reordena os meses
df_estacao# A tibble: 8,759 × 11
dia prec tmax tmin urmax urmin dirvent velvent rajada m tmed
<date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <dbl>
1 2022-01-01 0 21.2 20.2 100 99.0 0 0 0 1 20.7
2 2022-01-01 0 20.5 19.4 100 99.6 0 0 0 1 19.9
3 2022-01-01 0 19.7 19.0 100 99.9 0 0 0 1 19.3
4 2022-01-01 0 20.0 18.7 100 100 0 0 0 1 19.4
5 2022-01-01 0 20.5 19.8 100 100 0 0 0 1 20.2
6 2022-01-01 0 20.7 19.9 100 100 79.8 0.331 1.49 1 20.3
7 2022-01-01 0 20.2 19.1 100 100 0 0 0 1 19.7
8 2022-01-01 0 20.0 19.1 100 100 0 0 0 1 19.6
9 2022-01-01 0 22.1 0 100 0 0 0 0 1 11.0
10 2022-01-01 0 26.0 22.1 100 78.6 287. 0.087 2.09 1 24.0
# ℹ 8,749 more rowsGráficos
“O gráfico simples trouxe mais informações à mente do analista de dados do que qualquer outro dispositivo.” — John Tukey
O pacote ggplot2
O ggplot2 é um pacote R para produção de gráficos que diferentemente da maioria dos outros pacotes, apresenta uma profunda gramática baseada no livro The grammar of graphics (Wilkinson 2005)1. Os gráficos originados em ggplot2 são baseados em camadas, e cada gráfico tem três componentes chave: data, os dados de onde o gráfico será criado; aes() (aesthetic mappings), que controla o mapeamento estético e as propriedades visuais do gráfico; e ao menos uma camada que irá descrever como cada observação será renderizada. Camadas são usualmente criadas utilizando uma função geom_().
Galerias
- https://www.r-graph-gallery.com/portfolio/ggplot2-package/
- http://r-statistics.co/Top50-Ggplot2-Visualizations-MasterList-R-Code.html
- https://r4stats.com/examples/graphics-ggplot2/
- http://girke.bioinformatics.ucr.edu/GEN242/pages/mydoc/Rgraphics.html
Extensões do ggplot2
- http://www.ggplot2-exts.org/gallery/
- https://mode.com/blog/r-ggplot-extension-packages
Tutoriais em português
- https://rpubs.com/mnunes/ggplot2
- https://analisereal.com/2015/09/19/introducao-ao-ggplot2/
- https://timogrossenbacher.ch/2016/12/beautiful-thematic-maps-with-ggplot2-only/
- http://recologia.com.br/tag/graficos/
- http://rstudio-pubs-static.s3.amazonaws.com/24563_3b7b0a6414824e3b91769a95309380f1.html
- http://eduardogutierres.com/inteligencia-geografica-gerando-mapas-em-r/
- https://pt.stackoverflow.com/questions/332053/r-mapa-de-cidades-brasileiras
Meu primeiro gráfico em ggplot2
A seguir, vamos discutir os aspcetos básicos para a construção de gráficos utilizando o pacote ggplot2. A sintaxe do pacote patchwork é utilizada aqui para organizar os gráficos em forma de painéis.
As camadas de um gráfico ggplot2
No ggplot2, os gráficos são construídos camada por camada (ou, layers, em inglês). Neste exemplo, vamos confeccionar um gráfico mostrando a distribuição do comprimento da folha (eixo x) e largura da folha (eixo y).
p1 <-
ggplot(df, aes(x = comprimento, y = largura)) +
geom_point()
p1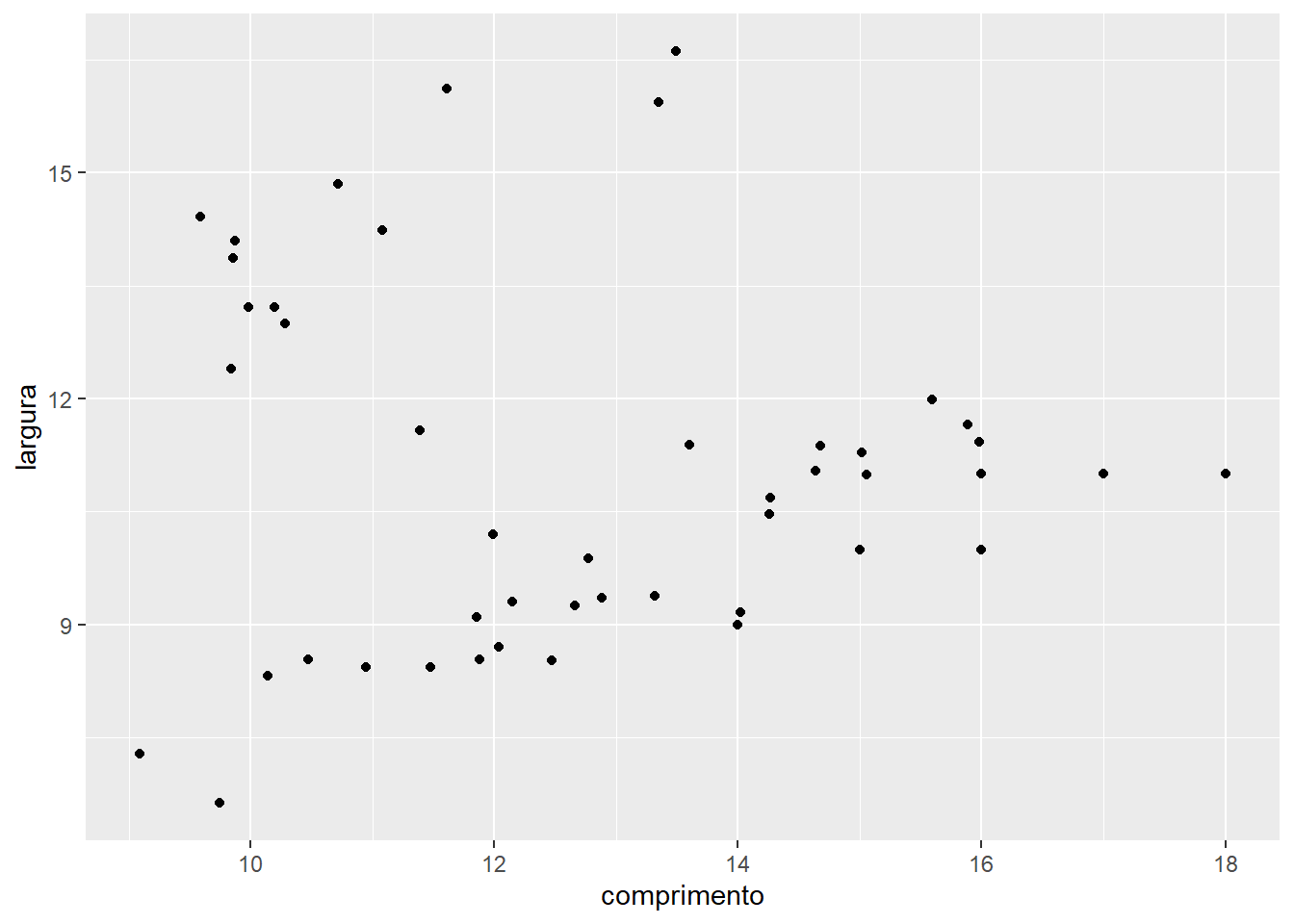
Este comando criou um gráfico e armazenou no objeto p1, que será plotado posteriormente. Observe que o primeiro argumento da função é o data frame onde nossos dados foram armazenados. A função aes() descreve como as variáveis são mapeadas (neste caso comprimento no eixo x e largura no eixo y). A função geom_point() definiu que a forma geométrica a ser utilizada é baseada em pontos, gerando, assim, um gráfico de dispersão. Isto é tudo que precisa ser feito para a confecção de um gráfico simples.
Aesthetics (estética)
“O maior valor de uma imagem é quando ela nos obriga a perceber o que nunca esperamos ver.” — John Tukey
Alterar a estética dos gráficos ggplot2 é uma tarefa relativamente simples. No gráfico anterior, os valores do comprimento e largura foram plotados sem nenhum tipo de mapeamento estético. Digamos que marcadores com diferentes cores para cada nível do fator cor poderia nos ajudar a compreender melhor o padrão presente em nossos dados. Vamos confeccionar este gráfico.
p2 <-
ggplot(df, aes(x = comprimento,
y = largura,
colour = cor)) +
geom_point()
p2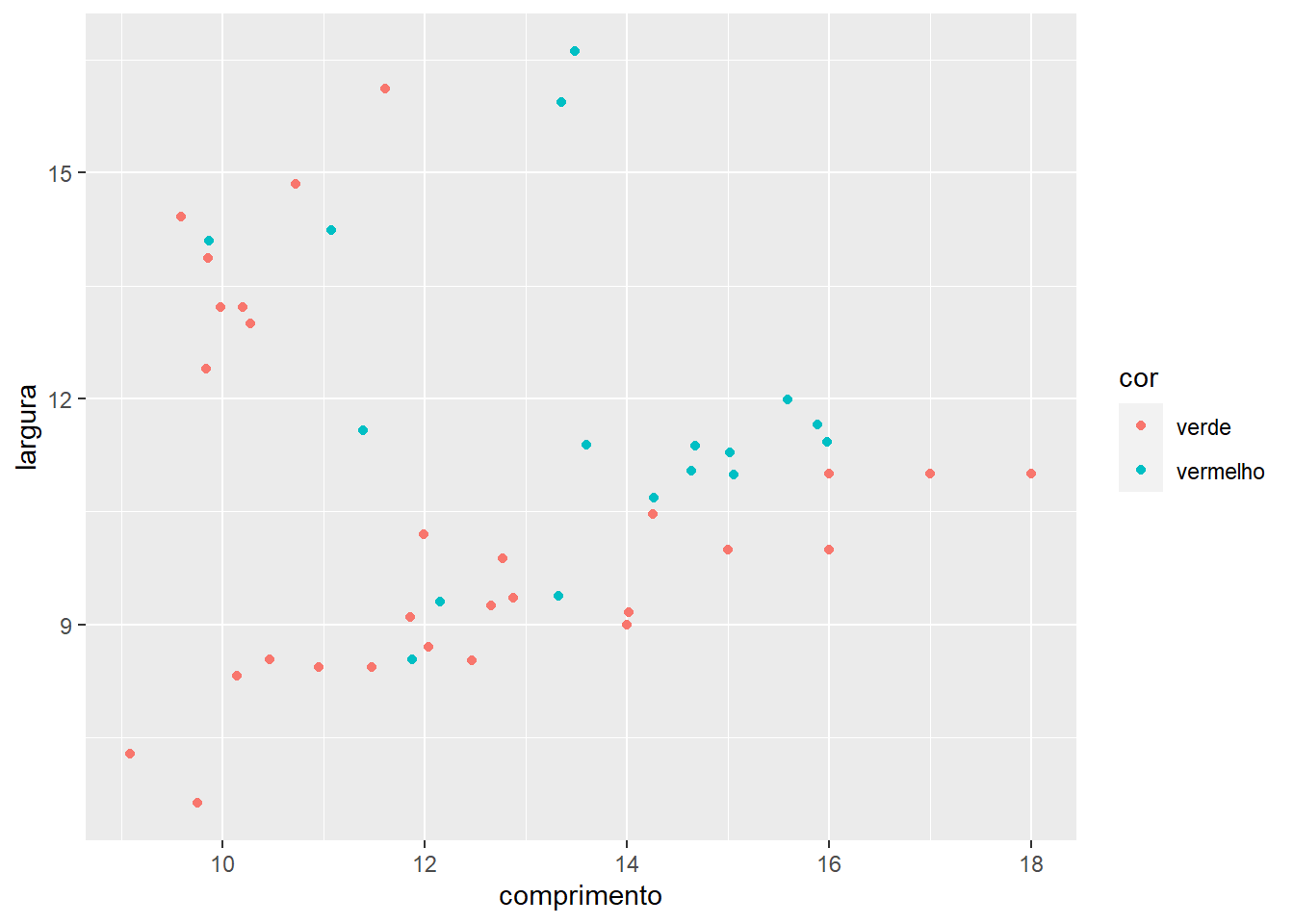
Ao incluirmos colour = cor dentro da função aes, dizemos ao ggplot que os pontos devem ser mapeados esteticamente (neste caso utilizando cores) para cada nível do fator cor presente em nossos dados. Digamos que em vez de utilizar diferentes cores, a cor do grão do café deveria ser representada por diferentes tipos de marcadores (quadrados, triângulo, etc.) Neste caso, o argumento colour = cor é substituído por shape = cor.
p3 <-
ggplot(df, aes(x = comprimento,
y = largura,
shape = cor,
color = cor)) +
geom_point()
# organizar os gráficos
(p1 | p2 | p3) +
plot_annotation(tag_levels = list(c("p1", "p2", "p3")))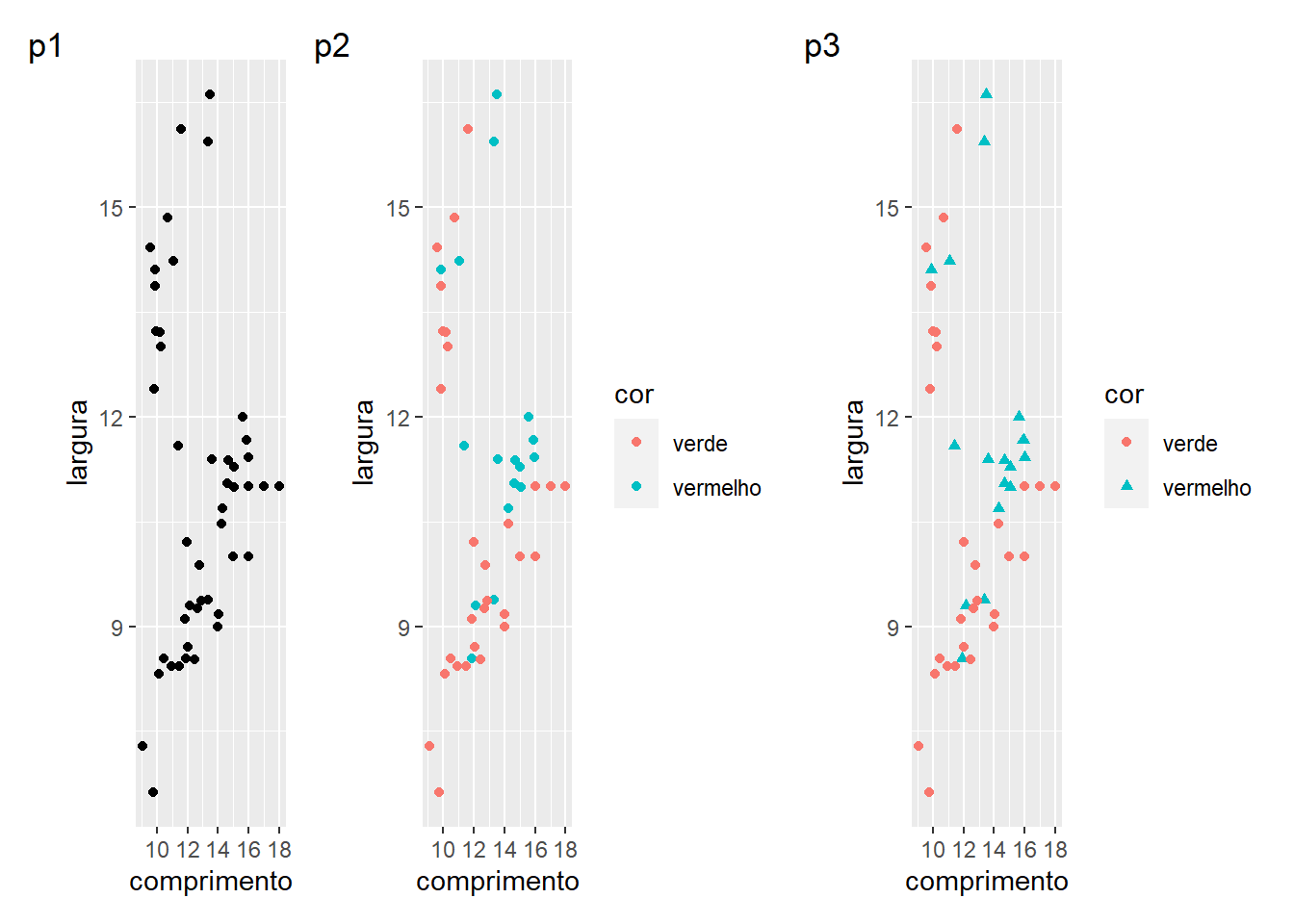
Salvar gráficos
A função ggsave() é uma função conveniente para salvar um gráfico. O padrão é salvar a última plotagem exibida, usando o tamanho do dispositivo gráfico atual. Também é possível informar a altura (height) e largura (width). Ele também adivinha o tipo de dispositivo gráfico da extensão. No seguinte exemplo, o gráfico acima é salvo no diretório de trabalho atual com o nome pontos.png, com 5 polegadas de altura e 10 de largura.
ggsave("pontos.png",
height = 5,
width = 10)Facet (facetas)
Mapeando os diferentes níveis de cor para diferentes cores, incluímos em um único gráfico os dados de todos osgrupos. Mas, e se nosso objetivo fosse realizar um gráfico para cada grupo? O ggplot2 tem uma poderosa ferramenta para isto: as funções facet_. Ao utilizar estas funções, o conjunto de dados é subdividido e um gráfico é construído para cada um destes subconjuntos. Vamos ver como elas podem nos ajudar em nosso problema.
fac1 <-
ggplot(df, aes(x = comprimento,
y = largura,
color = cor)) +
geom_point() +
facet_wrap(~ grupo)
fac1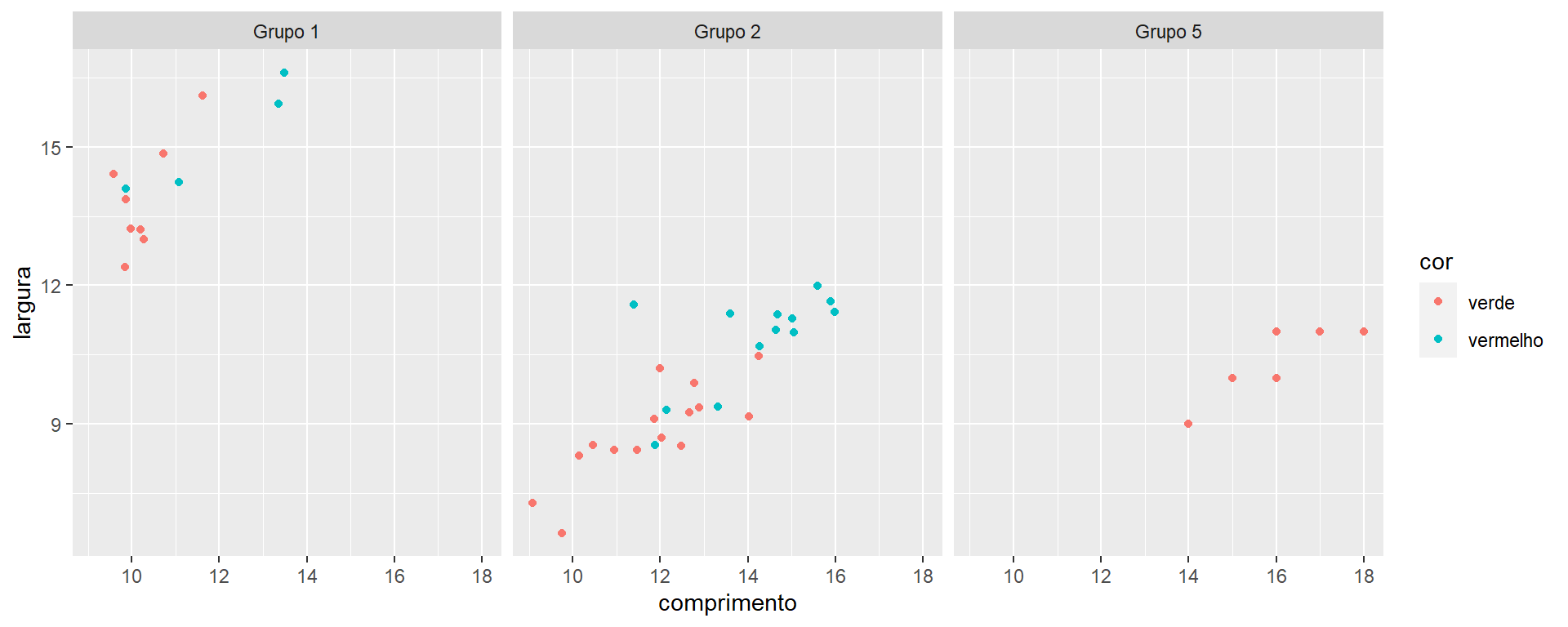
Neste exemplo, um gráfico completamente diferente do anterior é gerado com apenas uma simples adição: incluímos uma nova função, facet_wrap(~ grupo). Neste caso, informamos que um gráfico deveria ser realizado para cada grupo.
Theme (temas)
Cada gráfico criado com a função ggplot() tem um tema padrão. Tema, aqui, é toda propriedade relacionada ao aspecto visual do gráfico, que não foi definida na função aes() e que pode ser modificada utilizando a função theme() (veja ?theme). O ggplot2 já conta com alguns temas personalizados para facilitar nosso trabalho. Considerando o exemplo anterior, vamos utilizar a função theme_bw() (preto e branco) e a função theme() para modificar as propriedades visuais do gráfico.
fac2 <-
ggplot(df, aes(x = comprimento, y = largura, color = cor)) +
geom_point() +
facet_wrap(~ grupo) +
theme_light() +
theme(panel.grid.minor = element_blank(), # remove as linhas do corpo do gráfico
# sem bordas entre os painéis
panel.spacing = unit(0, "cm"),
# legenda abaixo do gráfico
legend.position = "bottom",
# modifica o texto dos eixos
axis.text = element_text(size = 12, colour = "black"),
# cor dos marcadores
axis.ticks = element_line(colour = "black"),
# tamanho dos marcadores
axis.ticks.length = unit(.2, "cm"),
#cor da borda
panel.border = element_rect(colour = "black", fill = NA, size = 0.5))+
# título dos eixos
labs(x = "Comprimento do grão (mm)", # título do eixo x
y = "Largura do grão (mm)", # título do eixo y
color = "") # título da legenda
wrap_plots(fac1, fac2, ncol = 1) +
plot_annotation(tag_levels = list(c("f1", "f2")))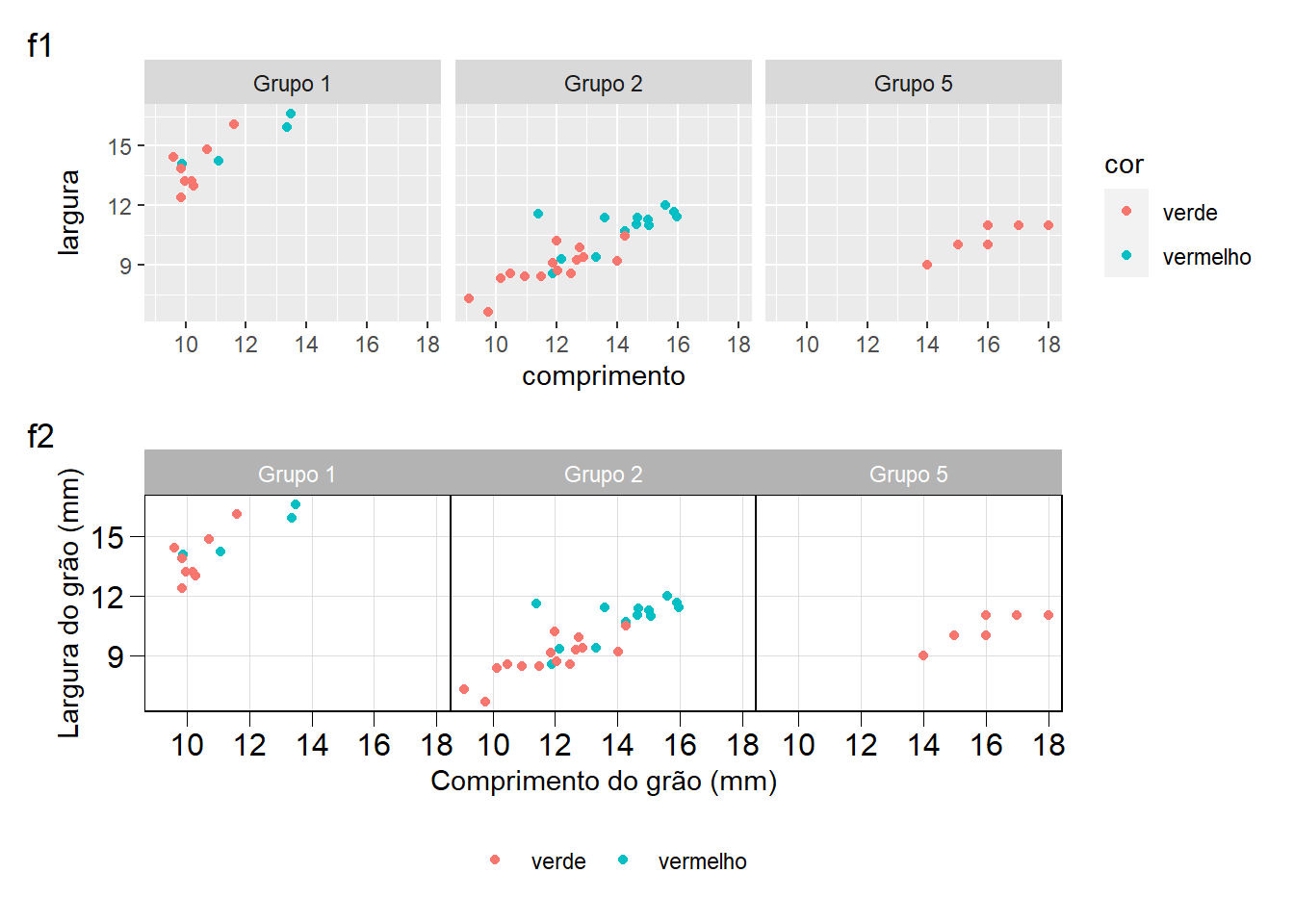
Os argumentos inseridos dentro das função theme() modificaram a aparência do nosso gráfico. Inúmeros outros argumentos são disponíveis, fazendo com que os gráficos originados sejam completamente personalizáveis. Digamos que precisamos confeccionar diversos gráficos e gostaríamos de manter o mesmo tema do gráfico acima. Seria exaustivo e desinteressante informar cada vez estes argumentos para cada gráfico, não? Felizmente, outra poderosa ferramenta proporcionada pelo ggplot2 é a possibilidade de confeccionarmos nossos próprios temas. Para isto, vamos executar o seguinte comando para criar um tema personalizado (my_theme()). Este tema pode então ser aplicado como uma camada adicional a cada gráfico que confecionarmos. Para evitar a necessidade da inclusão deste tema em cada gráfico gerado, iremos definir este tema como padrão utilizando a função theme_set().
my_theme <- function () {
theme_light() %+replace% # permite que os valores informados possam ser sobescritos
theme(axis.ticks.length = unit(.2, "cm"),
axis.text = element_text(size = 12, colour = "black"),
axis.title = element_text(size = 12, colour = "black"),
axis.ticks = element_line(colour = "black"),
panel.border = element_rect(colour = "black", fill = NA, size = 0.5),
panel.grid.minor = element_blank())
}
theme_set(my_theme())Geoms (geometria)
As funções geom_ definem qual forma geométrica será utilizada para a visualização dos dados no gráfico. Até agora, utilizamos a função geom_point()para construir gráficos de dispersão. Basicamente, qualquer outro tipo de gráfico pode ser criado dependendo da função geom_ utilizada. Dentre as diversas disponíveis no pacote ggplot2 as funções geom_ mais utilizadas são:
geom_abline(): para retas definidas por um intercepto e uma inclinação;geom_hline(): para retas horizontais definidas por um intercepty;geom_vline(): para retas verticais definidas por um interceptx;geom_boxplot(): para boxplots;geom_histogram(): para histogramas de frequência;geom_smooth(): ajusta uma função para o conjunto de dados e mostra uma banda de confiança;geom_density(): para densidades;geom_area(): para áreas;geom_bar(): para barras;geom_errorbar()para barras de erro;
Deste ponto em diante, vamos confeccionar alguns exemplos utilizando algumas destas funções (ou combinações destas funções) incluindo argumentos de mapeamento de estética e temas vistos até agora.
Linhas horizontais, verticais e diagonais
Três importantes geometrias são apresentadas a seguir:
geom_hline()adiciona uma linha horizontal definida por um intercepto emygeom_vline()adiciona uma linha vertical definida por um intercepto emx.geom_abline()adiciona uma linha diagonal definida por um intercepto e uma inclinação.
g1 <-
ggplot(df, aes(comprimento, largura)) +
geom_point()
g1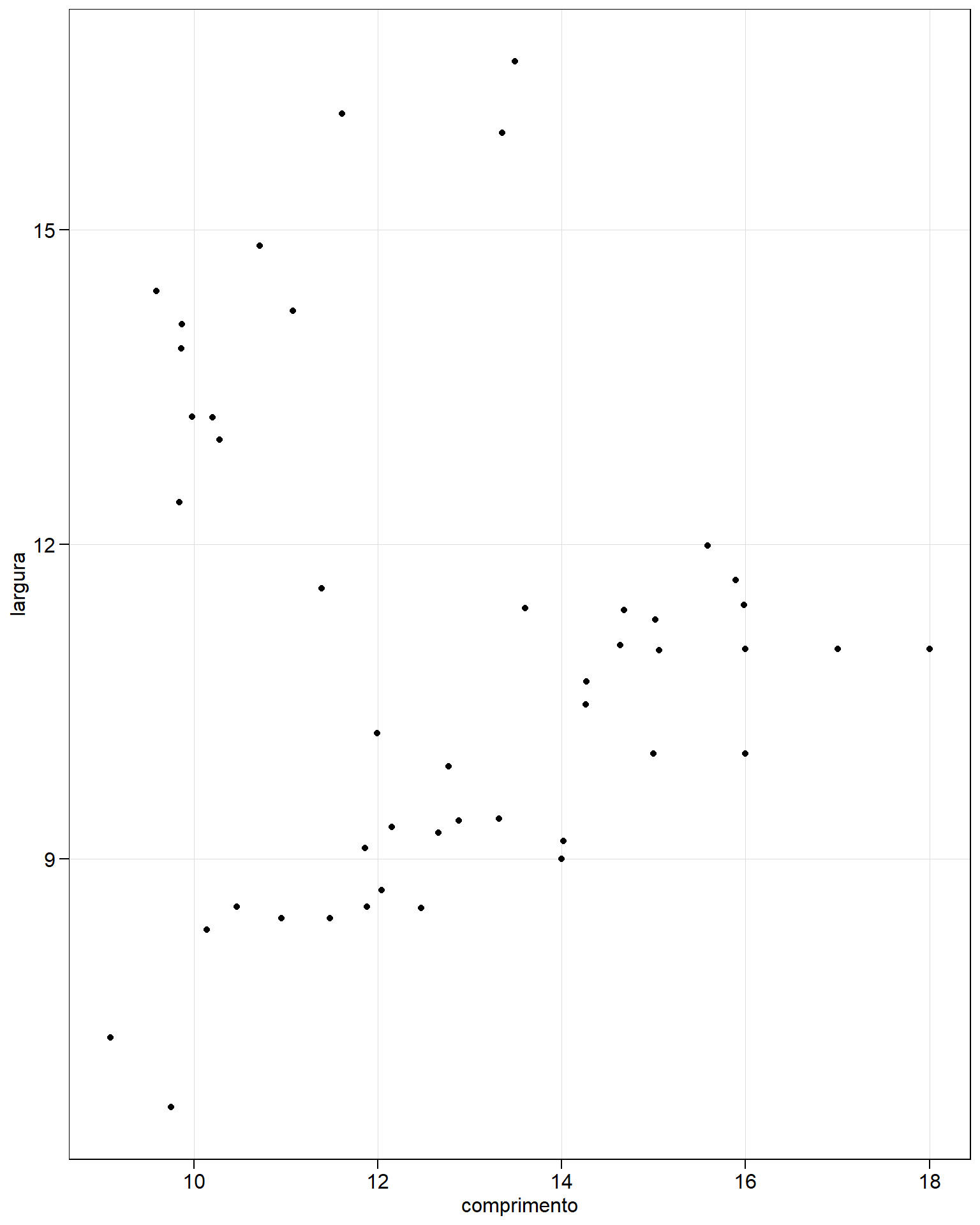
# adiciona linhas horizontais e verticais
g2 <-
g1 +
geom_hline(yintercept = mean(df$largura), color = "blue") +
geom_vline(xintercept = mean(df$comprimento), color = "red")
wrap_plots(g1, g2, ncol = 1) +
plot_annotation(tag_levels = list(c("g1", "g2")))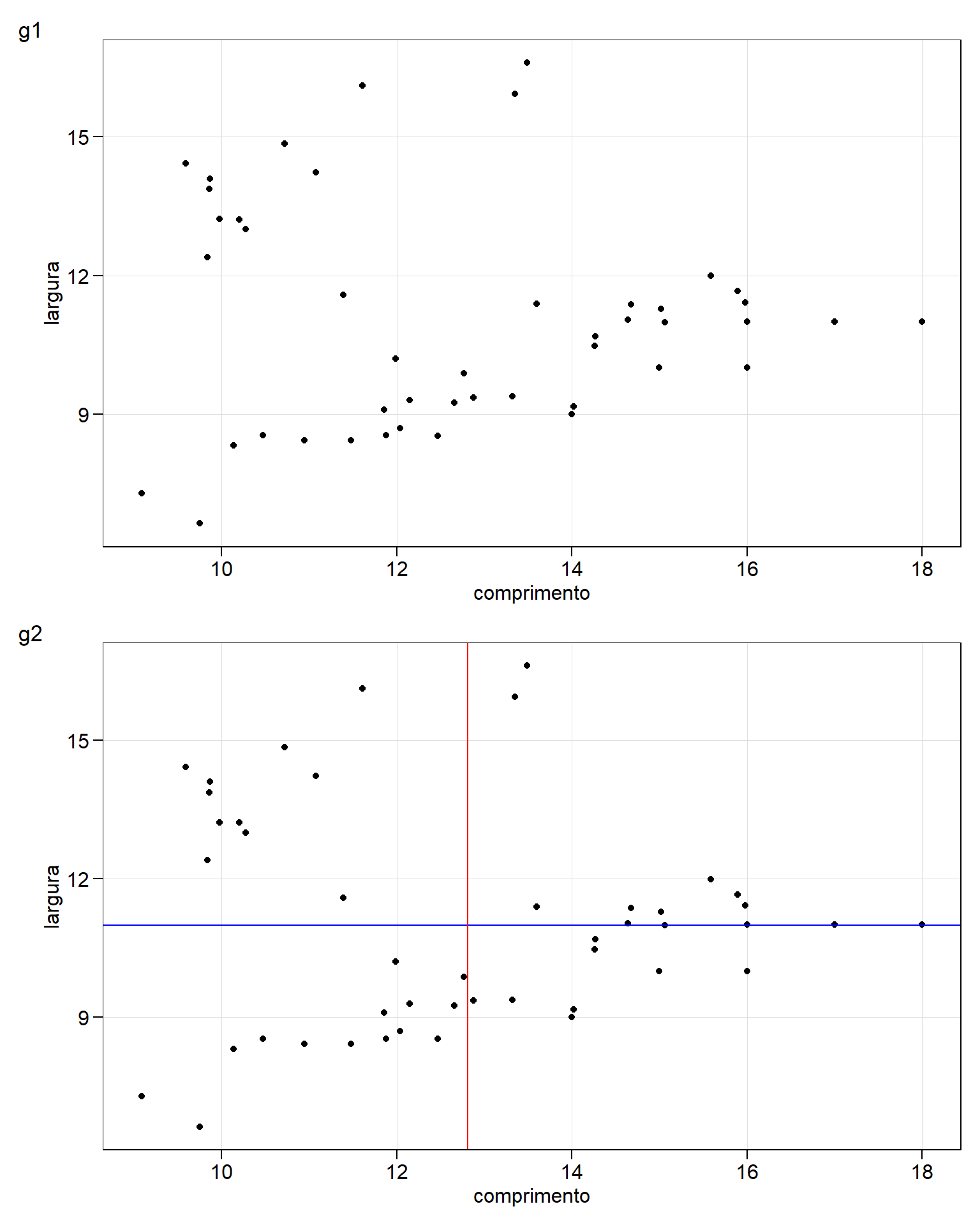
Gráficos do tipo boxplot
box1 <-
ggplot(df, aes(grupo, comprimento)) +
geom_boxplot()
box2 <-
ggplot(df, aes(grupo, comprimento)) +
geom_boxplot(outlier.colour = "transparent") +
geom_jitter(width = 0.1, color = "salmon")
box3 <-
ggplot(df, aes(grupo, comprimento, fill = cor)) +
geom_boxplot(width = 0.3) +
labs(x = "Grupo",
y = "Comprimento do grão (mm)") +
theme(legend.position = "bottom") +
scale_fill_manual(values = c("green", "red"))
((box1 + box2) / box3) +
plot_annotation(tag_levels = list(c("b1", "b2", "b3")))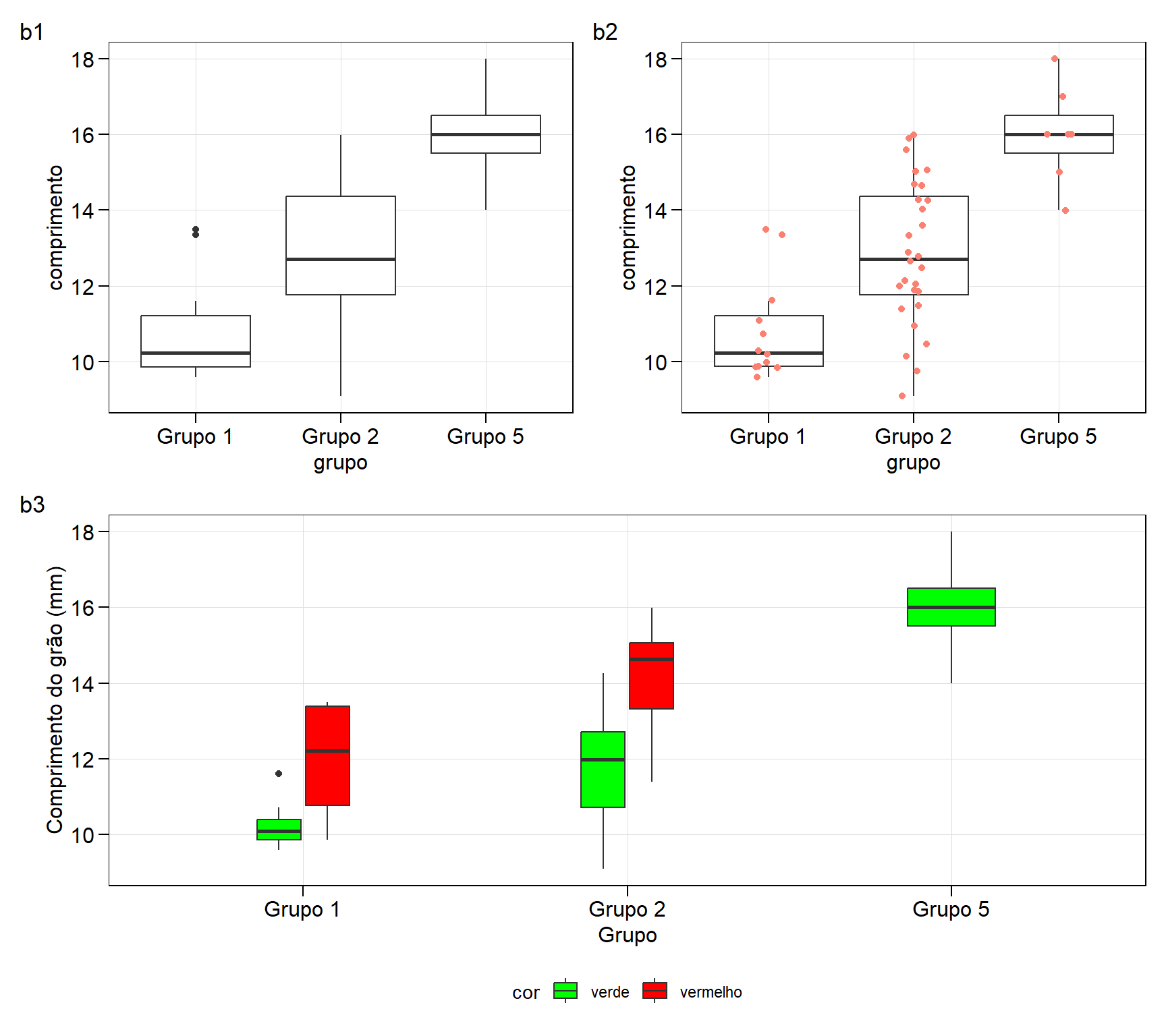
Cinco estatísticas são mostradas neste boxplot. A mediana (linha horizontal), as caixas inferior e superior (primeiro e terceiro quartil (percentis 25 e 75, respectivamente)). A linha vertical superior se estende da caixa até o maior valor, não maior que $1,5 $ (onde IQR é a amplitude interquartílica). A linha vertical inferior se estende da caixa até o menor valor, de no máximo, $1,5 $. Dados além das linhas horizontais podem ser considerados outliers.
Gráficos do tipo barra
No seguinte exemplo, os dados do comprimento do grão de café disponíveis em df são utilizados.
bar1 <-
ggplot(df, aes(x = grupo, y = comprimento)) +
geom_bar(stat = "summary", fun = "mean")
bar2 <-
ggplot(df, aes(x = grupo, y = comprimento, fill = cor)) +
stat_summary(fun = mean,
geom = "bar",
col = "black",
width = 0.8,
position = position_dodge(0.8)) +
stat_summary(fun.data = mean_se,
geom = "errorbar",
width = 0.2,
position = position_dodge(0.8))
(bar1 | bar2) +
plot_layout(widths = c(0.6, 1.2)) +
plot_annotation(tag_levels = list(c("bar1", "bar2")))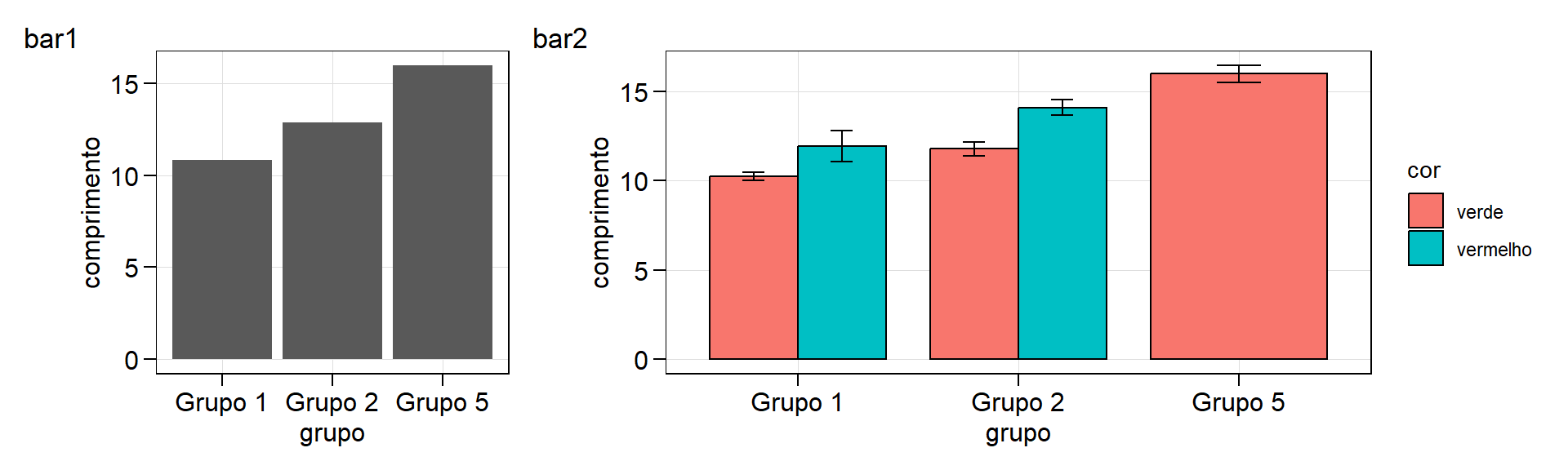
A afirmação de que um gráfico ggplot2 é feito em camadas fica mais evidente aqui. No gráfico bar1, as barras representam as médias geral do comprimento para cada grupo. No segundo gráfico, ao usar fill = cor informamos que as barras devem ser coloridas para cada nível do fator cor. A função stat_summary(), é vista pela primeira vez aqui, foi utilizada no segundo gráfico para substituir a função geom_bar(). Com isto, foi possível incluir as médias (fun = mean e geom = "bar), bem como as barras de erro (fun.data = mean_se e geom = "errorbar").
Utilizando a função plot_factbars() do pacote metan, um gráfico semelhante pode ser criado com as funções plot_bars() e plot_factbars()
metan1 <-
plot_bars(df,
x = grupo,
y = comprimento)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(where(is.numeric), round, digits = digits)`.
Caused by warning:
! There was 1 warning in `mutate()`.
ℹ In argument: `across(where(is.numeric), round, digits = digits)`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))
ℹ The deprecated feature was likely used in the metan package.
Please report the issue at <https://github.com/nepem-ufsc/metan/issues>.Warning in geom_bar(stat = "identity", width = width.bar, color = color.bar, :
Ignoring unknown parameters: `size`Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
ℹ The deprecated feature was likely used in the metan package.
Please report the issue at <https://github.com/nepem-ufsc/metan/issues>.metan2 <-
plot_factbars(df, # dados
grupo, cor, # dois fatores
resp = comprimento) # eixo yWarning in geom_bar(aes(fill = y), colour = "black", stat = "identity", :
Ignoring unknown parameters: `size`(metan1 | metan2) +
plot_layout(widths = c(0.6, 1.2)) +
plot_annotation(tag_levels = list(c("metan1", "metan2")))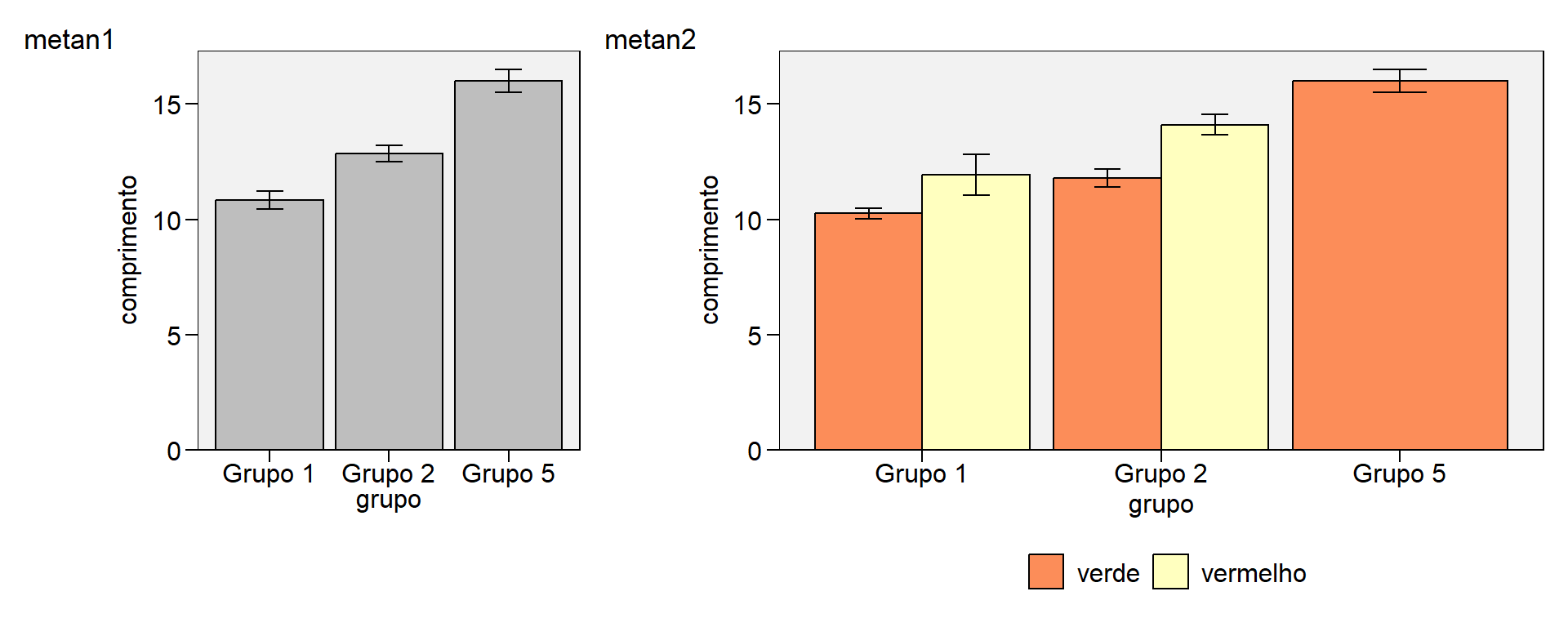
Gráficos do tipo histograma
Neste exemplo, utilizaremos os dados de temperatura média da estação meteorológica, disponível no data frame df_estacao. O primeiro histograma (p1) mostra os dados gerais desde 01/01/2022. No segundo, um histograma é gerado para cada mês.
h1 <-
ggplot(df_estacao, aes(x = tmed)) +
geom_histogram()
h2 <-
ggplot(df_estacao, aes(x = tmed)) +
geom_histogram(fill = "green") +
facet_wrap(~m) +
labs(x = "Temperatura média (ºC)",
y = "Número de horas")
(h1 | h2) +
plot_layout(widths = c(1, 1.4)) +
plot_annotation(tag_levels = list(c("h1", "h2")))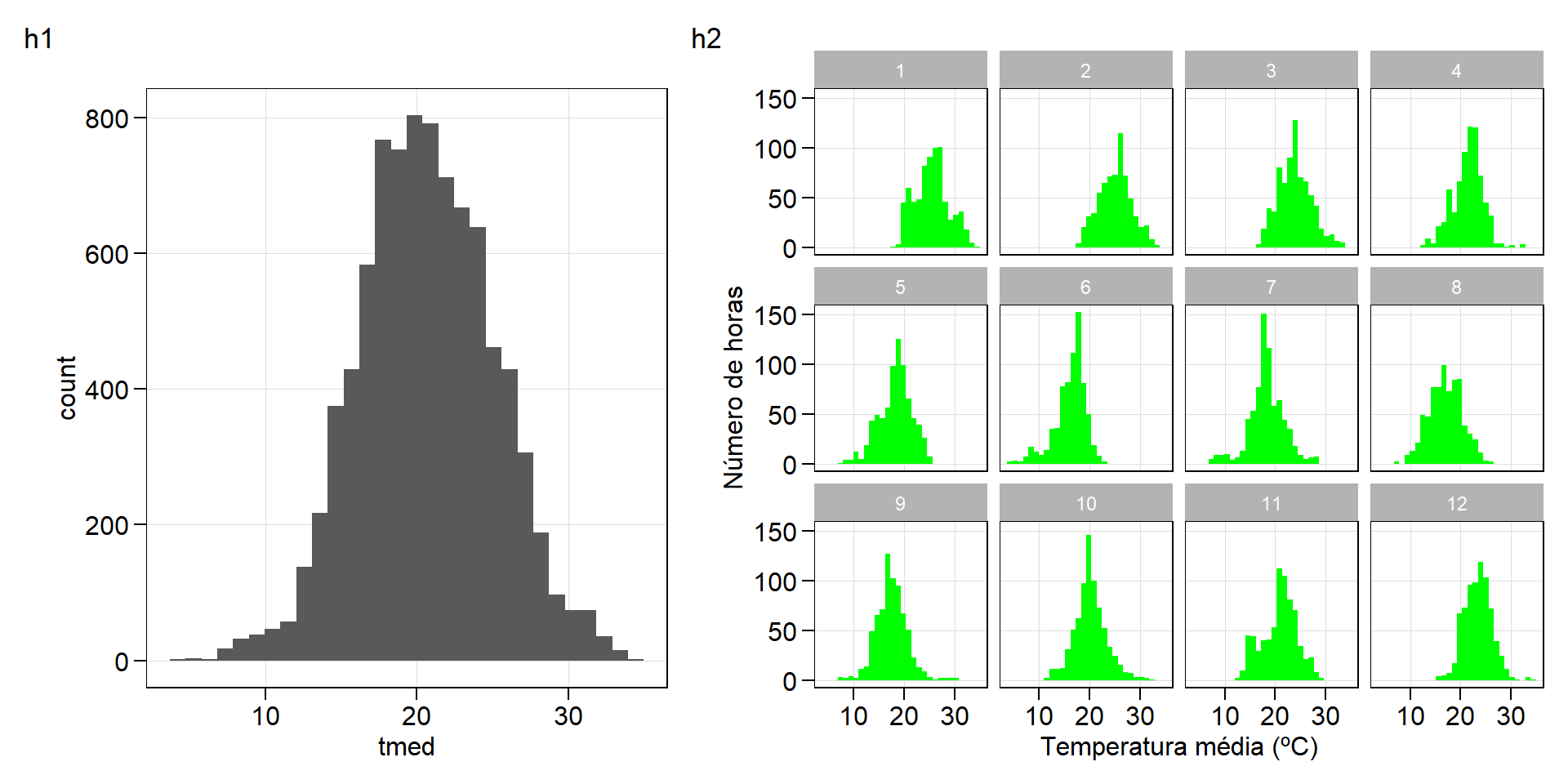
Gráficos de densidade
Os gráficos de densidade, têm a mesma interpretação que histogramas, no então são esteticamente mais atraente. Os primeiros dois exemplos nada mais são que a versão densidade dos histogramas apresentados anteriormente.
No terceiro exemplo (d3), é mostrado como é possível construir um gráfico de densidade ridges. Gráficos ridges são gráficos de linha parcialmente sobrepostos que criam a impressão de uma cordilheira. Eles podem ser bastante úteis para visualizar mudanças nas distribuições ao longo do tempo ou espaço2.
d1 <-
ggplot(df_estacao, aes(x = tmed)) +
geom_density()
d2 <-
ggplot(df_estacao, aes(x = tmed)) +
geom_density(color = "black",
fill = "skyblue") +
facet_wrap(~m, ncol = 6) +
labs(x = "Temperatura média (ºC)",
y = "Densidade")
d3 <-
ggplot(df_estacao, aes(x = tmed, y = m, fill = stat(x))) +
geom_density_ridges_gradient() +
scale_fill_viridis_c() +
labs(x = "Temperatura média (ºC)",
y = "Meses do ano",
fill = "Temperatura\nmédia (ºC)")
# agrupa os gráficos
wrap_plots(d1 + d2,
d3,
nrow = 2) +
plot_layout(heights = c(0.3, 0.7)) +
plot_annotation(tag_levels = list(c("d1", "d2", "d3")))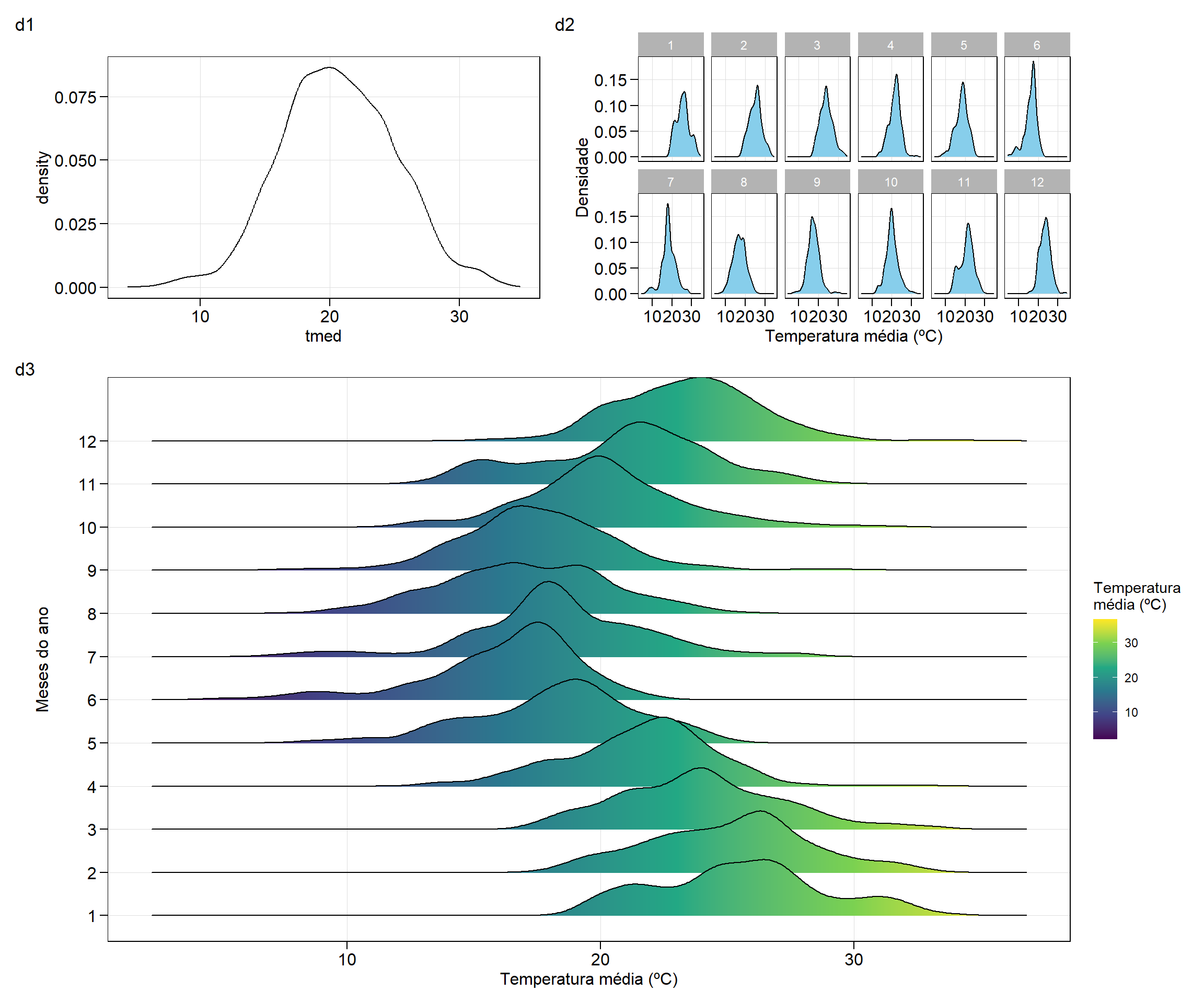
Gráficos de linhas
O seguinte exemplo mostra a temperatura mínima, média e máxima ao longo dos dias desde 01/01/2022. Primeiro, é preciso obter as temperaturas mínimas, máximas e médias de cada dia. Fazemos isso com a função summarise().
clima_max_min <-
df_estacao %>%
group_by(dia) %>%
summarise(max = max(tmax),
min = min(tmin),
mean = mean(tmed),
precip = sum(prec)) %>%
pivot_longer(-dia)
clima_max_min# A tibble: 1,460 × 3
dia name value
<date> <chr> <dbl>
1 2022-01-01 max 28.7
2 2022-01-01 min 0
3 2022-01-01 mean 23.6
4 2022-01-01 precip 0
5 2022-01-02 max 31.8
6 2022-01-02 min 23.4
7 2022-01-02 mean 27.1
8 2022-01-02 precip 0
9 2022-01-03 max 32.4
10 2022-01-03 min 24.3
# ℹ 1,450 more rows# realiza um subset para remover a precipitação
df_temp <-
clima_max_min |>
subset(name != "precip")
# faz o gráfico de linhas
ggplot(df_temp, aes(dia, value, color = name, group = name)) +
geom_point() +
geom_line() +
scale_color_manual(values = c("red", "green", "blue"),
labels = c("Temperatura máxima (ºC)",
"Temperatura média (ºC)",
"Temperatura mínima (ºC)"),
guide = "legend") +
scale_x_date(date_breaks = "3 week", # marcação a cada duas semanas
date_labels = "%d/%m/%y") + # formato dd/mm/aa
theme(legend.position = "bottom",
axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)) +
labs(title = "Temperaturas máximas, médias e mínimas em 2022",
subtitle = "Estação - Fazenda Ressacada",
caption = "Elaboração: Prof. Olivoto",
x = "Dia do ano",
y = "Temperatura (ºC)",
color = NULL) # remove o título da legenda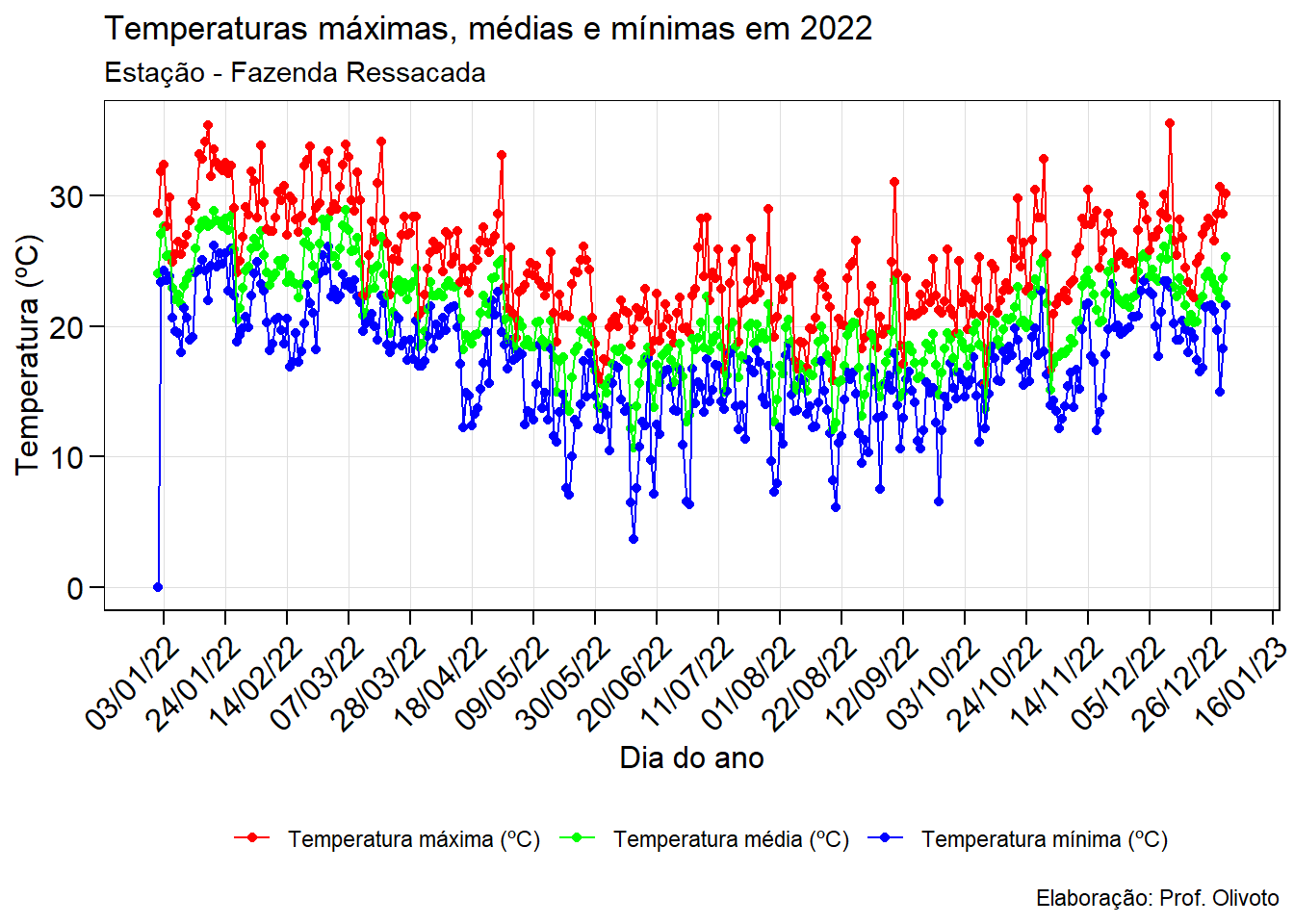
Linha de regressão (linear)
l1 <-
ggplot(df, aes(x = comprimento, y = largura)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) + # estima uma regressão linear
labs(x = "Comprimento do grão",
y = "Largura do grão")
l2 <-
ggplot(df, aes(x = comprimento, y = largura, color = grupo)) +
geom_point() +
geom_smooth(method = "lm", se = F)+
labs(x = "Comprimento do grão",
y = "Largura do grão")
(l1 | l2) +
plot_layout(widths = c(1, 1.2)) +
plot_annotation(tag_levels = list(c("s1", "s2")))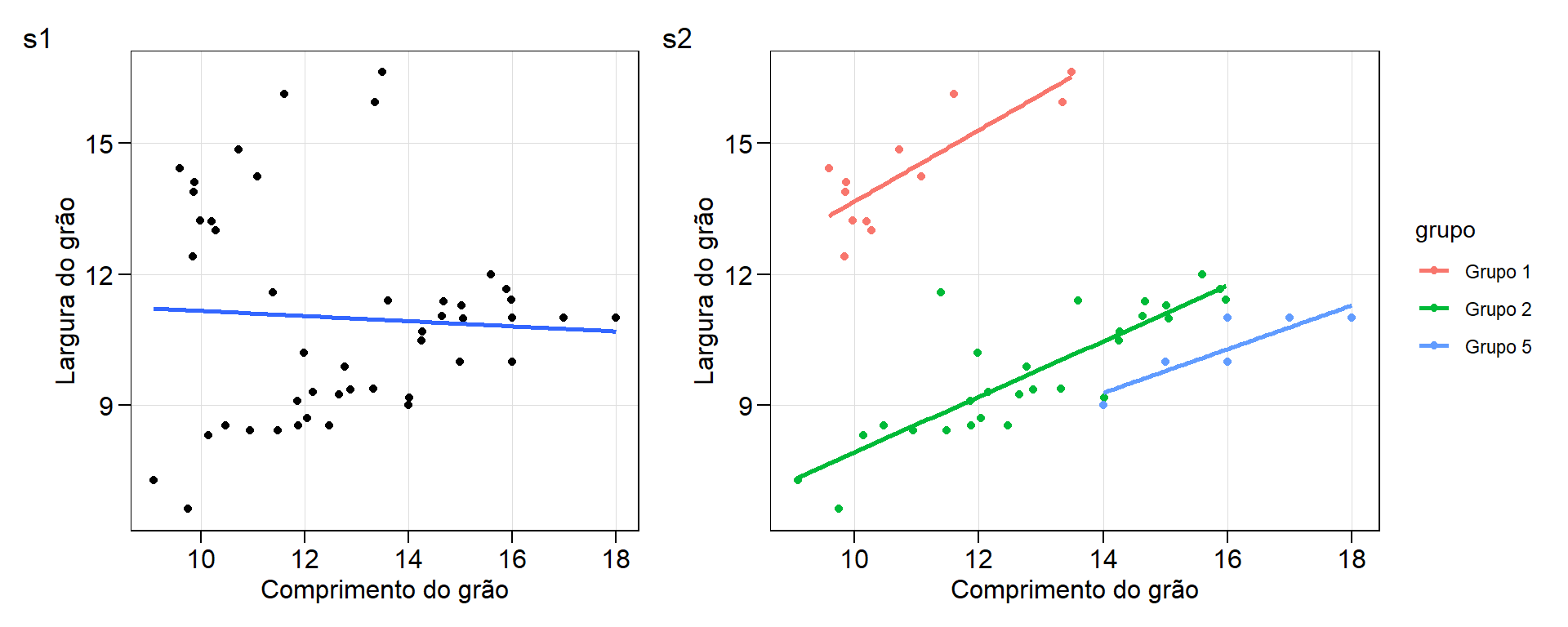
Linha de regressão (polinomial)
Para confeccionar um gráfico de regressão polinomial, além do argumento method = "lm" (linear model), precisa-se incluir no argumento formula a formula utilizada, neste caso, definida utilizando poly() (polinomial).
#### Polinômio de segundo grau
dado_reg <- tibble(dose = c(15,20,25,30,35,40),
prod = c(65,70,73,75,69,62))
q1 <-
ggplot(dado_reg, aes(dose, prod))+
geom_point()+
stat_smooth(method = "lm",
formula = "y ~ poly(x, 1)",
se = FALSE)
q2 <-
q1 +
stat_smooth(method = "lm",
formula = "y ~ poly(x, 2)",
linetype = "dashed",
color = "red",
se = FALSE)
(q1 | q2) + plot_annotation(tag_levels = list(c("l1", "l2")))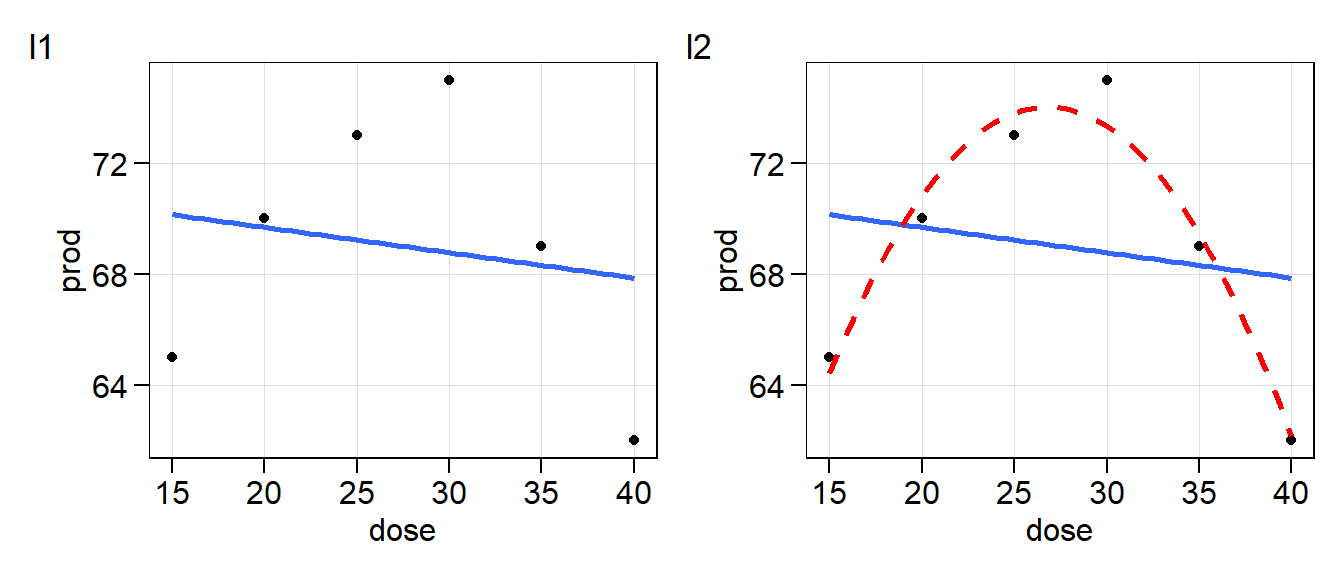
Utilizando a função plot_lines() do pacote metan, um gráfico semelhante pode ser criado com
plot_lines(dado_reg,
x = dose,
y = prod,
fit = 2)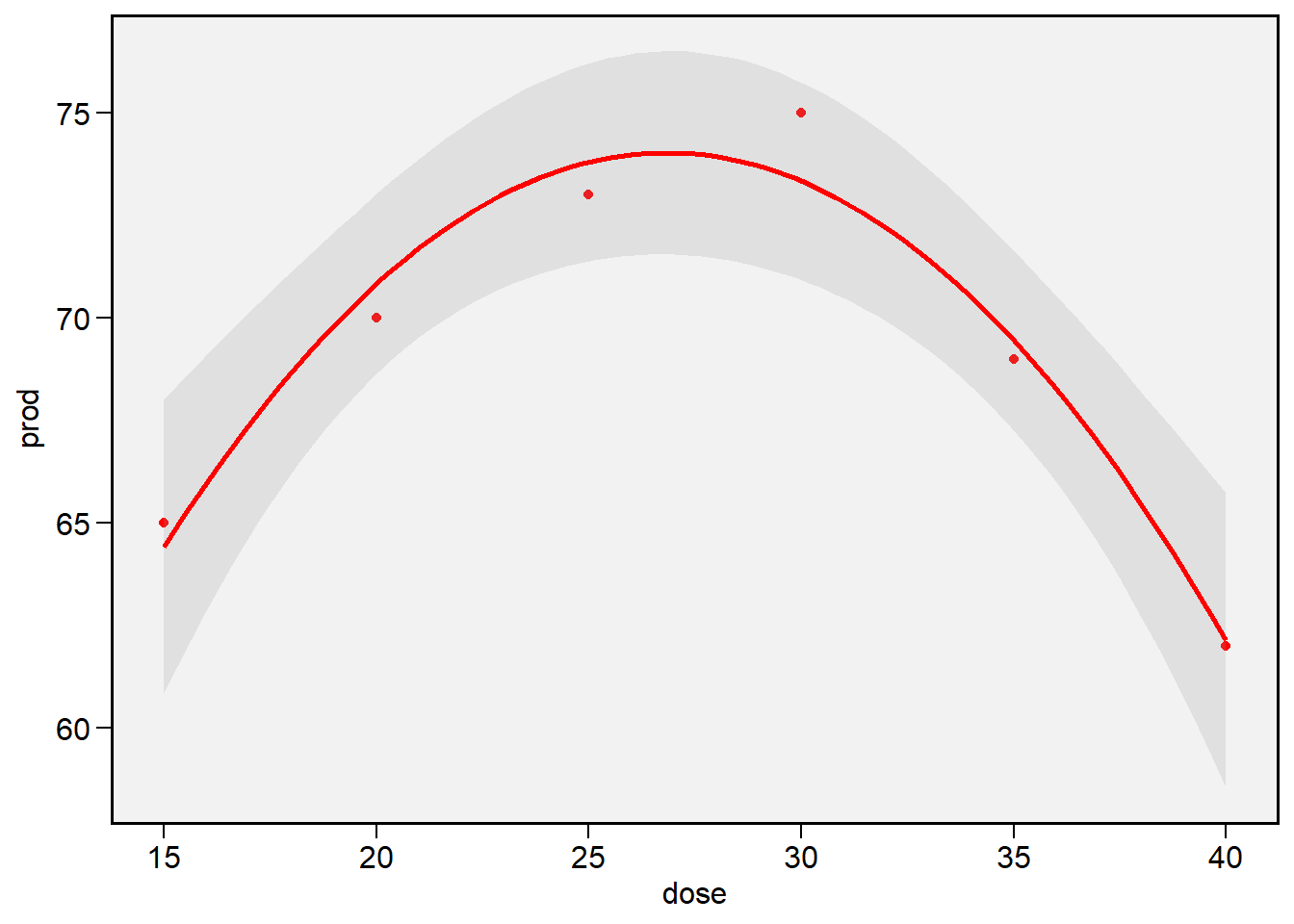
Dados da estação
Exploração dos dados
plot_intro(df_estacao)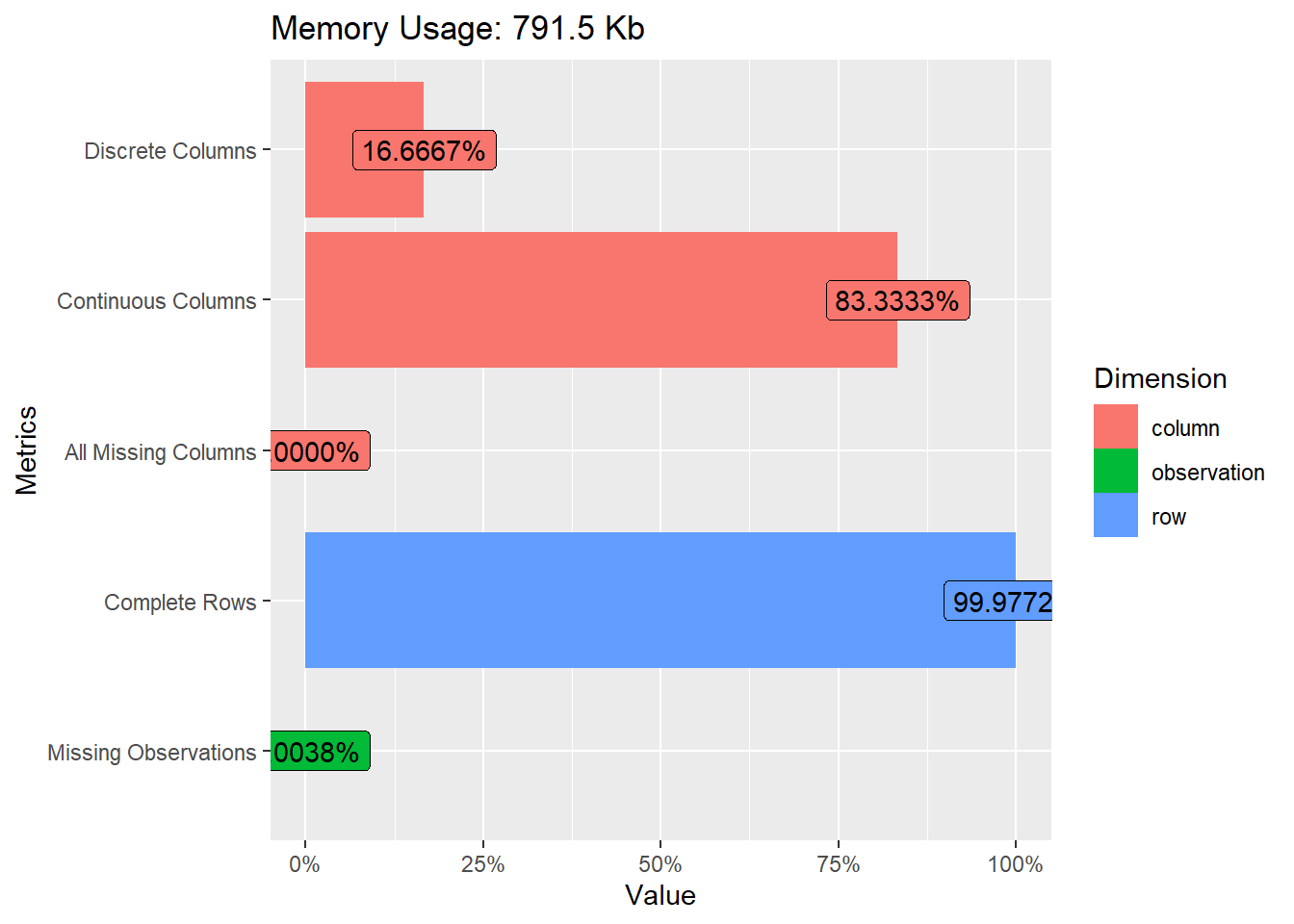
# Colunas numéricas
plot_histogram(df_estacao, ncol = 5)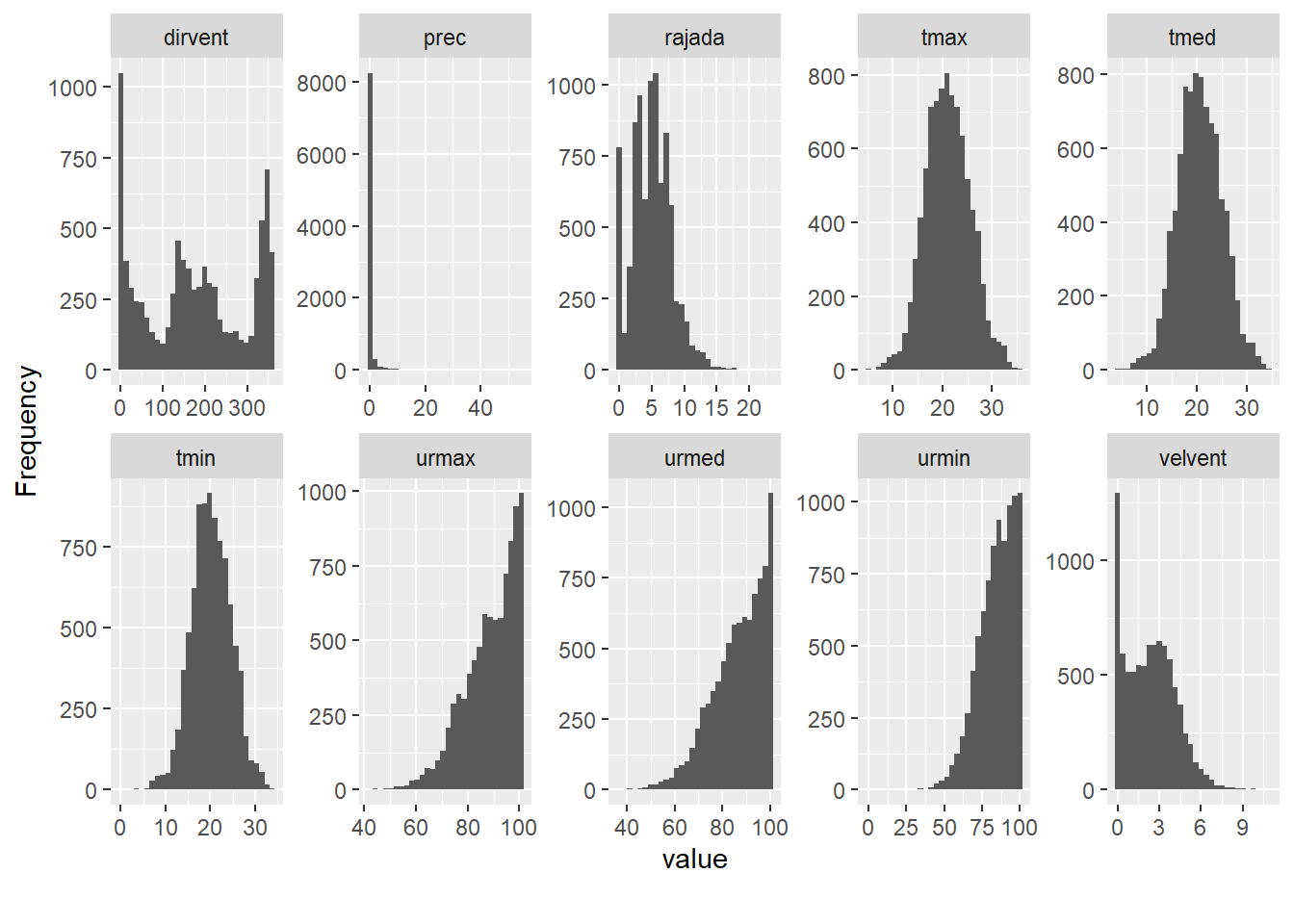
Gráfico da precipitação e temperatura
#| out-width: "100%"
df_prec <-
clima_max_min |>
pivot_wider(names_from = "name",
values_from = "value")
ggplot() +
geom_bar(df_prec,
mapping = aes(x = dia, y = precip * 30 / 100),
stat = "identity",
fill = "skyblue") +
geom_line(df_prec,
mapping = aes(x = dia, y = max, colour = "red"),
size = 1) +
geom_line(df_prec,
mapping = aes(x = dia, y = min, colour = "blue"),
size = 1) +
scale_x_date(date_breaks = "15 days", date_labels = "%d/%m",
expand = expansion(c(0, 0)))+
scale_y_continuous(name = expression("Temperatura ("~degree~"C)"),
sec.axis = sec_axis(~ . * 100 / 30 , name = "Precipitação (mm)")) +
theme(legend.position = "bottom",
legend.title = element_blank(),
axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)) +
scale_color_identity(breaks = c("red", "blue"),
labels = c("Temperatura máxima (ºC)",
"Temperatura mínima (ºC)"),
guide = "legend") +
labs(x = "Dia do ano")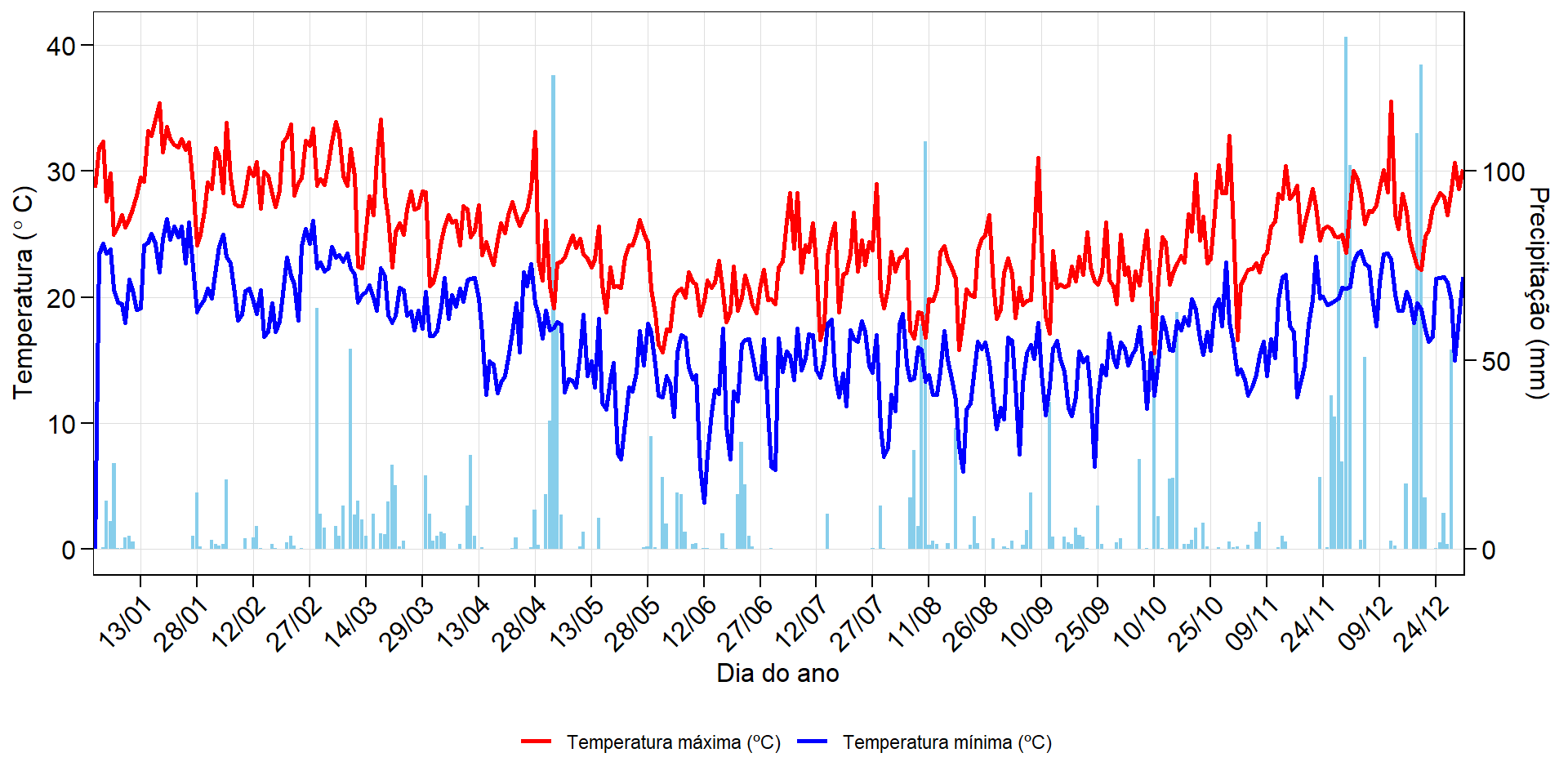
Velocidade média do vento
vento_long <-
df_estacao %>%
select(m, dia, velvent) %>%
pivot_longer(-c(m, dia))
# confeccionar gráfico
ggplot(vento_long, aes(m, value, color = name, group = name )) +
stat_summary(geom = "point",
fun = mean) +
stat_summary(geom = "line") +
stat_summary(geom = "errorbar", width = 0.1) +
scale_color_manual(values = c("red", "blue"),
labels = c("Rajada (m/s)",
"Velocidade do vento (m/s)"),
guide = "legend") +
theme(panel.grid.minor = element_blank(),
legend.position = "bottom",
legend.title = element_blank(),
axis.title = element_text(size = 12),
axis.text = element_text(size = 12)) +
labs(title = "Velocidade média mensal do vento em 2022",
subtitle = "Estação UFSC - Ressacada",
caption = "Elaboração: Prof. Tiago Olivoto",
x = "Mês do ano",
y = "Velocidade (m/s)")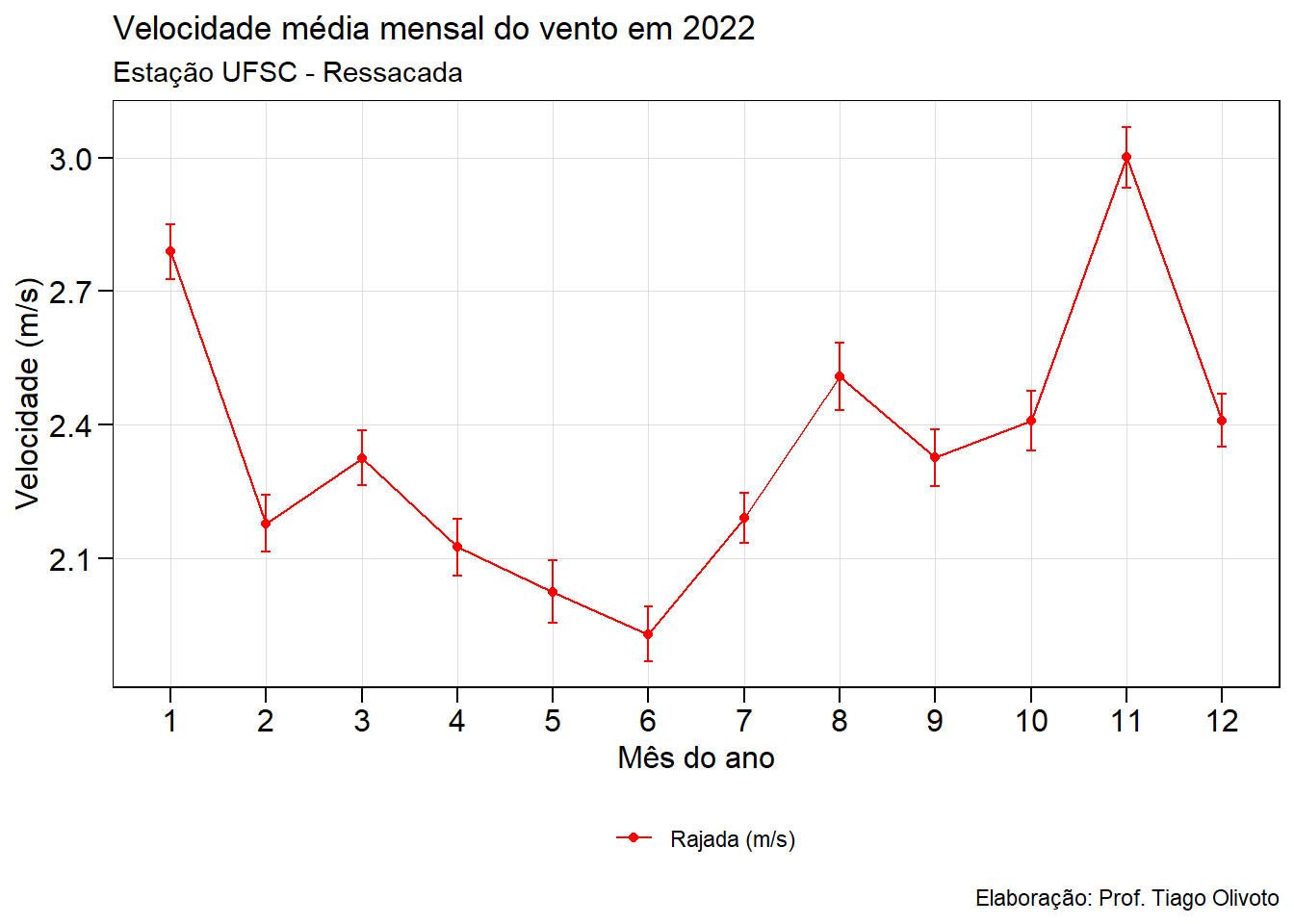
Direção do vento
# cria uma tabela de frequência transformando a variável quantitativa direção do vento
# em uma qualitativa usando a função cut()
freq <-
df_estacao %>%
group_by(m) %>%
mutate(quadrante = cut(dirvent,
breaks = seq(0, 360, by = 45),
right = FALSE)) |>
group_by(m, quadrante) |> # conta as horas por mes e por quadrante
count() |> # conta as horas por mes e por quadrante
group_by(m) |> # agrupa por mes
mutate(percent = n / sum(n)) |> # converte em percentagem
select(m, quadrante, percent) |>
pivot_wider(names_from = quadrante, values_from = percent) |>
set_names(c("mes", paste0(seq(0, 315, by = 45)))) |>
column_to_rownames("mes") |>
slice(2, 11)
# altera o nome das colunas para pontos cardeais
names(freq) <- c("N", "NE", "L", "SE", "S", "SO", "O", "NO")
freq
## N NE L SE S SO O
## 2 0.2098214 0.08779762 0.04613095 0.04464286 0.1577381 0.07142857 0.09970238
## 11 0.1319444 0.04305556 0.08750000 0.20138889 0.2250000 0.08472222 0.07361111
## NO
## 2 0.2827381
## 11 0.1527778
# define o máximo da frequência e o mínimo da frequência
# isso vai definir o quao expandido e contraído ficará o radar
maxmim <- data.frame(rbind(rep(0.4, 8), rep(0, 8)))
names(maxmim) <- c("N", "NE", "L", "SE", "S", "SO", "O", "NO")
# junta as frequências com os máximos e mínimos
freqrad <- rbind(maxmim, freq)
# inverte a ordem das colunas para ficar certo na rosa dos ventos
freqrad <- freqrad[,c(1, seq(8, 2))]
library(fmsb) # pacote para criar o radar
# https://r-charts.com/ranking/radar-chart/
areas <- c(rgb(1, 0, 0, 0.3),
rgb(0, 1, 0, 0.3))
radarchart(freqrad,
seg = 3,
axistype = 4,
caxislabels = paste0(c(0, 10, 20, 30), "%"),
pcol = c("red", "green"),
pfcol = areas)
legend("topright",
legend = c("Junho", "Novembro"),
bty = "n",
pch = 20,
col = areas,
text.col = "grey25",
pt.cex = 2)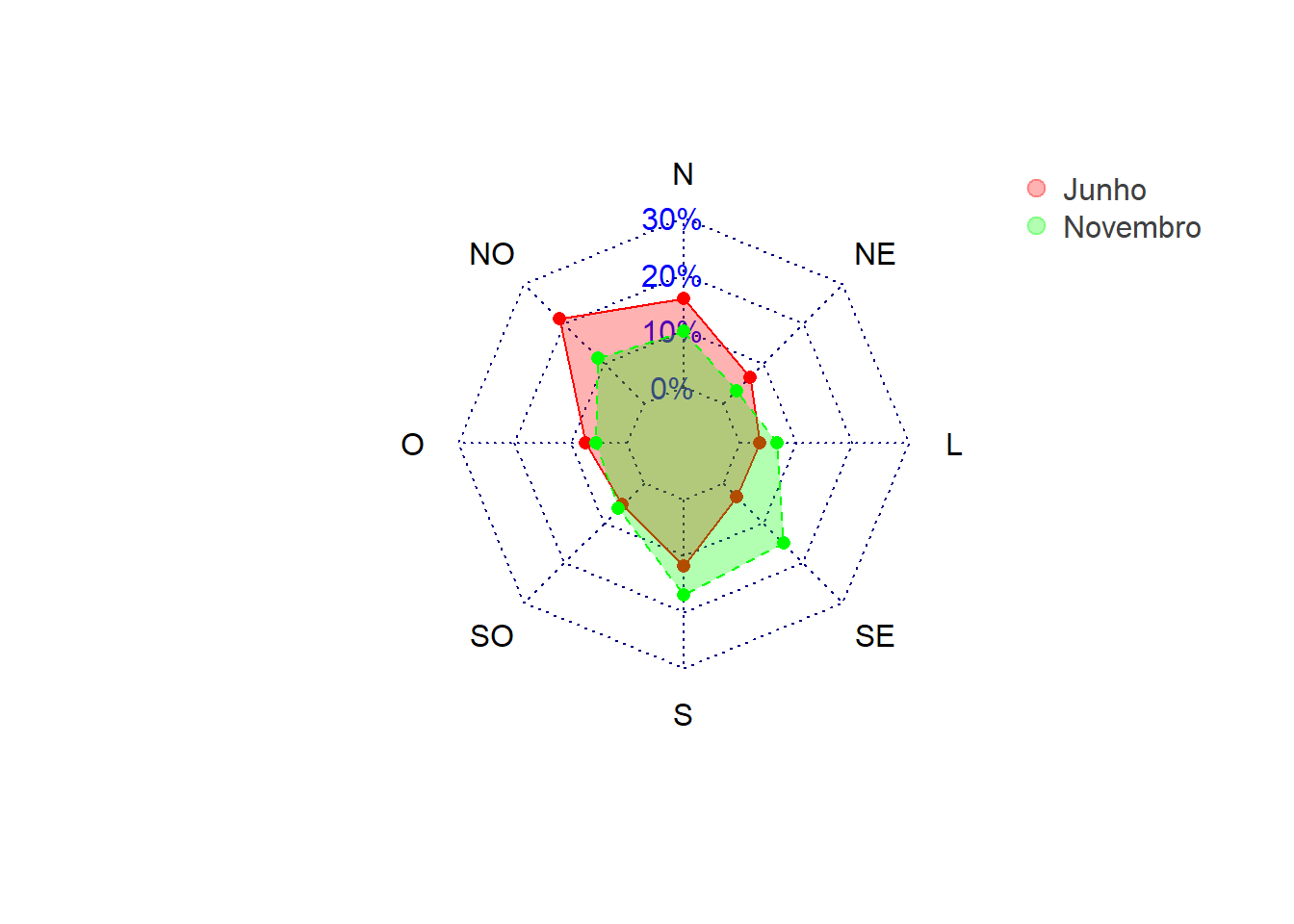
Mapas
Mapa da américa do sul e Brasil
O pacote rnaturalearth é uma excelente ferramenta para manter e facilitar a interação com os dados do mapa Natural Earth. Para produção de mapas com o ggplot2, os seguintes pacotes são necessários.
#| out-width: "100%"
# américa do sul
library(rnaturalearth)
library(tidyverse)
sam <-
ne_countries(continent = "south america",
returnclass = "sf",
scale = 50)
p1 <-
ggplot() +
geom_sf(data = sam, fill = "white") +
theme_light() +
xlim(c(-90, -35))
# plotar o brasil e destacar santa catarina
brazil <-
ne_states(country = "brazil", returnclass = "sf") |>
mutate(scat = ifelse(postal == "SC", "SC", "Outros"))
p2 <-
p1 +
geom_sf(data = brazil, aes(fill = scat))
p2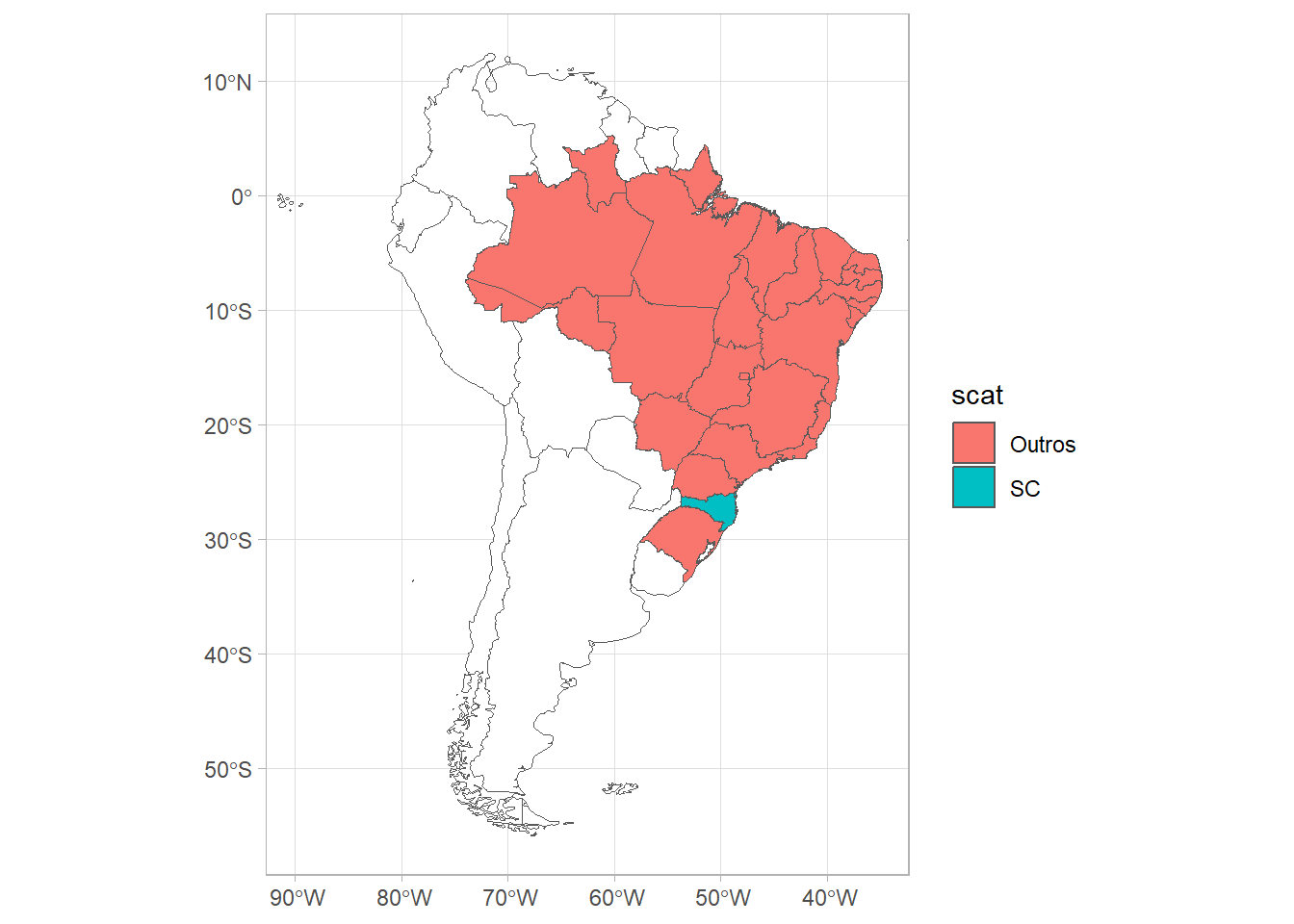
Mapa do Brasil e SC, com municípios
sc <-
read_municipality(code_muni = "SC",
simplified = FALSE,
showProgress = FALSE) |>
mutate(floripa = ifelse(name_muni == "Florianópolis",
"Florianópolis",
"Outro"))Using year/date 2010p3 <-
p1 +
geom_sf(data = brazil) +
geom_sf(data = sc, aes(fill = floripa)) +
xlim(c(-55, -47)) +
ylim(c(-30, -25)) +
labs(title = "Mapa do brasil destacando o estado de SC",
caption = "Produzido com os pkgs geobr e rnaturalearth",
fill = "") +
theme(legend.position = "bottom")Scale for x is already present.
Adding another scale for x, which will replace the existing scale.p3
O pacote esquisse
O pacote esquisse ajuda a explorar e visualizar dados de forma interativa. Ele é uma interface Shiny para criar gráficos ggplot interativamente usando “arrastar e soltar” para mapear suas variáveis. Pode-se visualizar rapidamente os dados de acordo com seu tipo, exportar para formatos raster (ex., .png, .jpg) ou vetor (ex., .pdf, .eps) e recuperar o código para reproduzir o gráfico.
Para inciar a criação do gráfico, basta carregar o pacote e executar o comando esquisser(). Uma janela aparecerá, onde será possível importar um conjunto de dados, ou utilizar um conjunto de dados existente no ambiente R.
esquisser()
Após selecionar o conjunto de dados, as variáveis existentes ficarão disponíveis para serem mapeadas. Basta clicar e arrastar! Para ter uma maior área de trabalho do pacote, sugere-se definir a opção para que a interface gráfica do pacote seja aberta no navegador. Para isso, rode options("esquisse.viewer" = "browser").
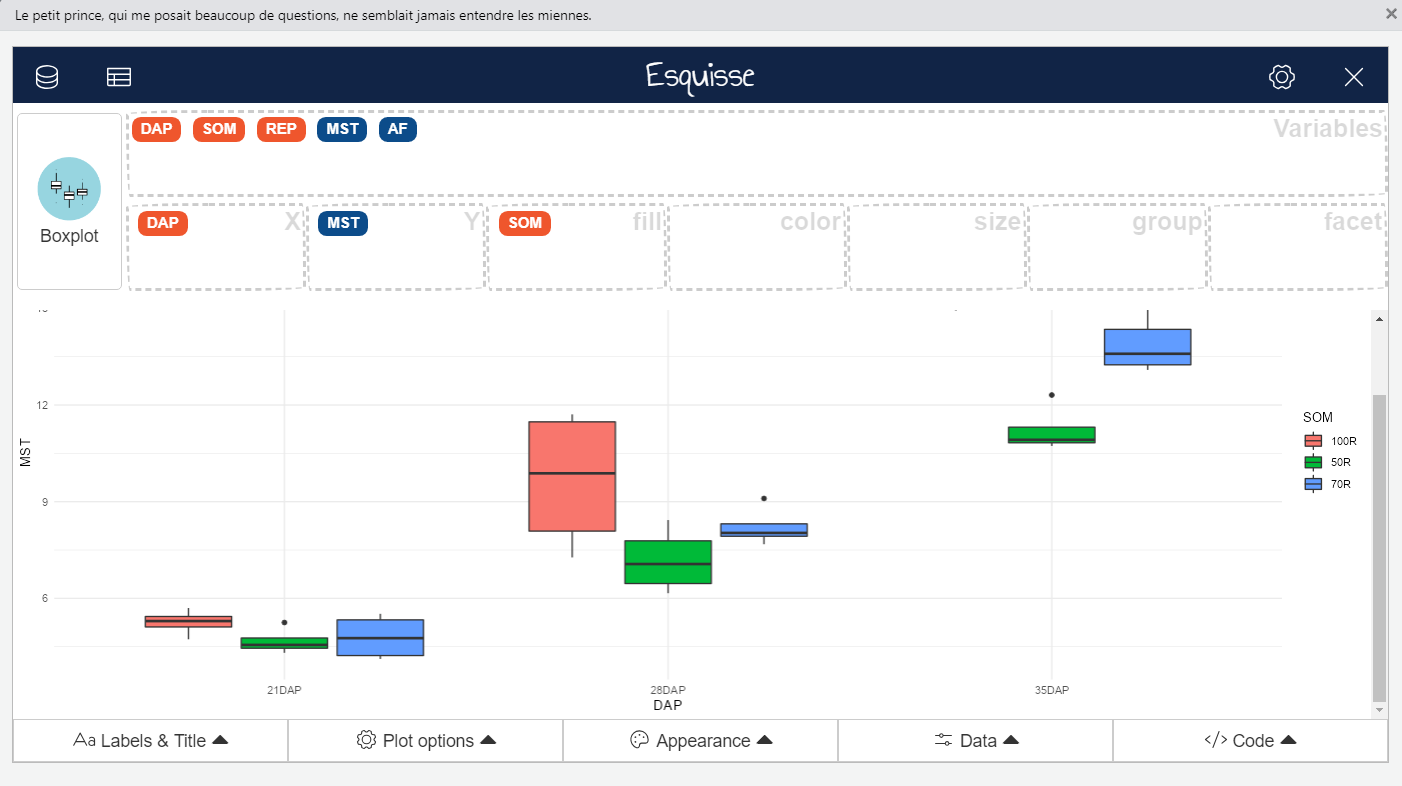
Exercício
Motivação
A densidade de fluxo de fótons fotossintéticos (PPFD) em níveis subótimos ou superótimos pode modificar o acúmulo de biomassa, composição bromatológica e aparência das culturas. Para isso, Olivoto et al. (2018)3 investigaram o efeito de níveis de radiação no crescimento da chicória (Cichorium endivia L. var. latifolia). Os dados disponíveis na aba chicoria do conjunto de dados examples_data.xlsx são relativos a duas variáveis, à saber, matéria seca total (MST) e área foliar (AF) de plantas de chicória cultivadas em diferentes níveis de sombreamento (50, 70, e 100), e avaliados aos 21, 28 e 35 dias após o plantio.
df <- import("examples_data.xlsx",
sheet = "chicoria",
setclass = "tbl")
df# A tibble: 36 × 5
DAP SOM REP MST AF
<chr> <chr> <chr> <dbl> <dbl>
1 21DAP 50R B1 4.31 847.
2 21DAP 50R B2 5.25 1607.
3 21DAP 50R B3 4.50 1320.
4 21DAP 50R B4 4.61 1567.
5 21DAP 70R B1 4.12 1206.
6 21DAP 70R B2 5.52 1863.
7 21DAP 70R B3 5.27 1774.
8 21DAP 70R B4 4.26 1307.
9 21DAP 100R B1 5.24 1203.
10 21DAP 100R B2 5.70 1299.
# ℹ 26 more rowsPara lapidar os conhecimentos na construção de gráficos, utilize o pacote ggplot24 e metan5 para solução dos seguintes problemas.
Problema 1 - Associação entre variáveis
- Considerando os dados, construa um gráfico de dispersão com a variável
AFno eixo x e a variávelMSTno eixo y, salve o gráfico em um objeto chamadop1.
p1 <-
ggplot(df, aes(AF, MST)) +
geom_point()- Para melhor compreender a distribuição dos pontos, realize o mapeamento da variável
DAPcom diferentes cores. - Altere a legenda do eixo x e y para ‘Área foliar (cm2)’ e ‘Matéria seca (g)’, respectivamente.
- Aplique um tema de sua preferência ao tema utilizando qualquer tema definido por
theme_*()6. - Armazene o gráfico em um objeto chamado
p2.
p2 <-
ggplot(df, aes(AF, MST, color = DAP)) +
geom_point() +
labs(x = "Área foliar (cm2)",
y = "Matéria seca (g)")- Organize os gráficos
p1ep2em um mesmo painel, um ao lado do outro.
p1 | p2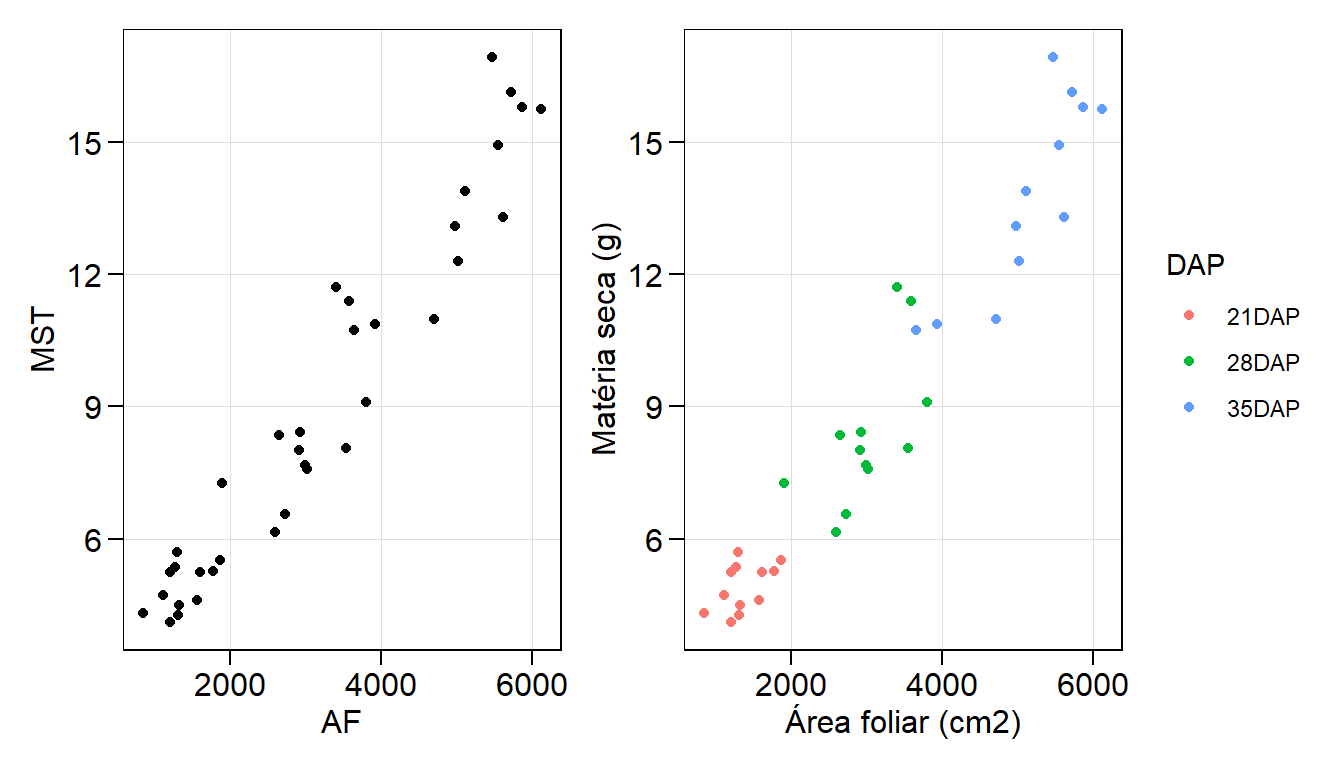
- Realize a interpretação do gráfico com relação à associação entre AF e MST.
A área foliar e a matéria seca estão positivamente relacionadas, ou seja, há a tendêncida de que o aumento na área foliar venha acompanhado do aumento na matéria seca. No segundo gráfico, é possível identificar que os maiores valores de matéria seca e área foliar foram observados nos 35DAP, e o menores, aos 21DAP.
- Salve os gráficos em um arquivo chamado
dispersão.png, com 3 polegadas de altura e 8 de largura
ggsave("dispersão.png", width = 8, height = 3)Problema 2 - Variação dos dados
- Confeccione um gráfico do tipo boxplot contendo a variável
DAPno eixo x eMSTno eixo y. Salve o gráfico em um objeto chamadop3.
p3 <-
ggplot(df, aes(DAP, MST)) +
geom_boxplot()- Para fazer inferências sobre o fator sombreamento, construa um boxplot semelhante, mas agora mapeando a variável
SOMcom diferentes cores de preenchimento do boxplot. * Inclua uma linha horizontal que represente a média geral da matéria seca. - Salve o gráfico em um objeto chamado
p4.
p4 <-
ggplot(df, aes(DAP, MST, fill = SOM)) +
geom_boxplot() +
geom_hline(yintercept = mean(df$MST))- Organize os gráficos
p3ep4em um mesmo painel, um ao lado do outro.
p3 | p4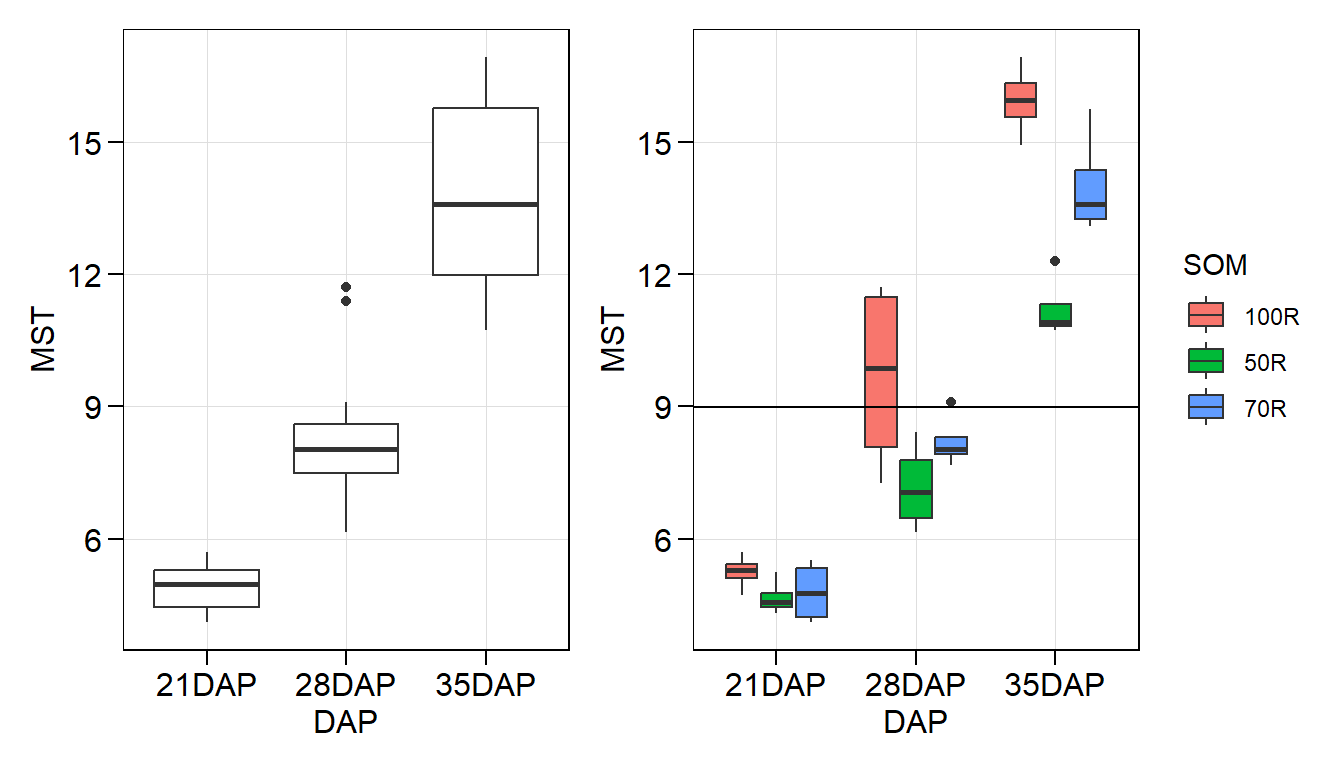
- Realize a interpretação do gráfico com relação à variação da matéria seca total entre os diferentes níveis de radiação dentro de cada dia após o plantio.
Aos 21DAP foi observada a menor variação entre os níveis de SOM. Aos 28DAP, a diferença entre os níveis de SOM foi mais evidente, onde plantas crescendo em 100R apresentaram um valor mediano de MST maior, mas também a maior variação entre as repetições (comprimento da caixa). Aos 35DAP, a diferença entre as radiações torna-se mais evidente. Também, pode-se observar que as variações entre as repetições do 100R e 50R foram menores se comparado aos 28DAP (menor comprimento da caixa).
- Salve os boxplots em um arquivo chamado
boxplot.png.
ggsave("boxplot.png")Problema 3 - Médias
- Confeccione um gráfico de barras mostrando a média da variável
AFno eixo y para cada dia após o plantio (DAP) no eixo x. - Defina os limites do eixo y de 0 até 6000.
- Salve o gráfico em um objeto chamado
p5.
Dica: a função plot_bars() do pacote metan pode ser útil.
p5 <-
plot_bars(df,
x = DAP,
y = AF,
y.lim = c(0, 6000))Warning in geom_bar(stat = "identity", width = width.bar, color = color.bar, :
Ignoring unknown parameters: `size`# versão ggplot2
p5.2 <-
ggplot(df, aes(DAP, AF)) +
geom_bar(stat = "summary") +
ylim(c(0, 6000))- Assumindo que as médias da AF precisam ser apresentadas para cada combinação de DAP e SOM, mapeie a variável
SOMcom diferentes cores de preenchimento no gráfico de barras. - Mude os títulos dos eixos x e y para “Dias após o plantio (DAP)” e “Área foliar (cm2)”, respectivamente.
- Defina os limites do eixo y de 0 até 6000.
- Armazene o gráfico em um objeto chamado
p6. - Organize os gráficos
p5ep6em um único painel - Salve os gráficos de barra em uma imagem chamada
barras.png.
Dica: a função plot_factbars() do pacote metan pode ser útil.
p6 <-
plot_factbars(df, DAP, SOM,
resp = AF,
y.lim = c(0, 6000),
xlab = "Dias após o plantio (DAP)",
ylab = "Área foliar (cm2)")Warning in geom_bar(aes(fill = y), colour = "black", stat = "identity", :
Ignoring unknown parameters: `size`# versão ggplot2
p6.2 <-
ggplot(df, aes(DAP, AF, fill = SOM)) +
geom_bar(stat = "summary",
fun = "mean",
width = 0.7,
position = position_dodge()) +
stat_summary(fun.data = mean_se,
geom = "errorbar",
width = 0.2,
position = position_dodge( width = 0.7)) +
labs(x = "Dias após o plantio (DAP)",
y = "Área foliar (cm2)") +
ylim(c(0, 6000))- Organize os gráficos
p5ep6em um mesmo painel, um ao lado do outro.
p5 | p6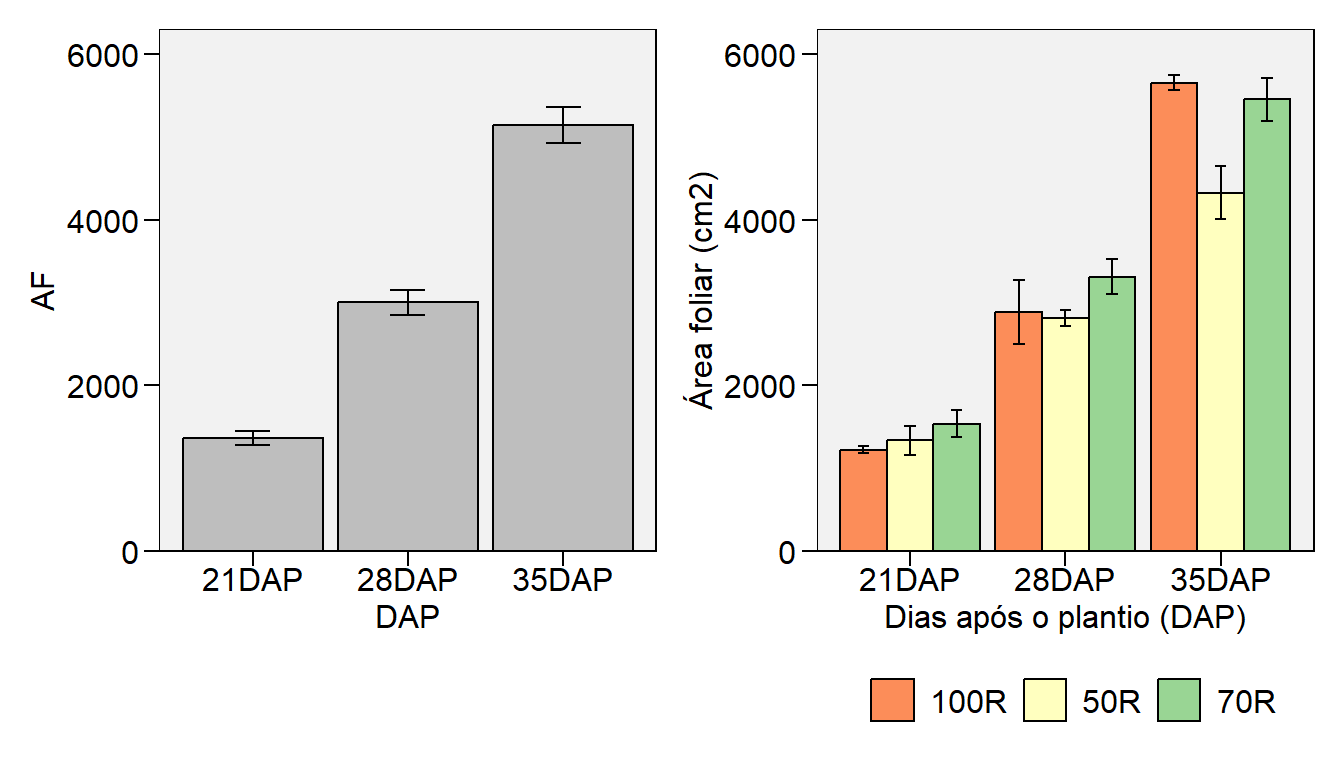
- Realize a interpretação do gráfico com relação à área foliar nos diferentes níveis de radiação ao longo dos dias após o plantio.
A média da área foliar foi mais semelhante entre os níveis de radiação aos 21DAP. Considerando o erro padrão da média como uma medida de significância, pode-se afirmar que aos 21DAP as médias do 50R e 70R foram estatisticamente iguais. Aos 35DAP, a área foliar das plantas crescendo com 50% de radiação foi menor que àquelas crescendo em pleno sol (100R) e com 70% de radiação (70R).
- Salve os boxplots em um arquivo chamado
barras.png.
ggsave("barras.png")Referências
Footnotes
WICKHAM, H. Ggplot2 : elegant graphics for data analysis: Springer, 2009.↩︎
https://cran.r-project.org/web/packages/ggridges/vignettes/introduction.html↩︎
OLIVOTO, T. et al. Photosynthetic photon flux density levels affect morphology and bromatology in Cichorium endivia L. var. latifolia grown in a hydroponic system. Scientia Horticulturae, v. 230, p. 178–185, 7 jan. 2018.↩︎
WICKHAM, H. ggplot2: Elegant Graphics for Data Analysis. New York: Springer, 2016.↩︎
OLIVOTO, T.; LÚCIO, A. D. metan: An R package for multi‐environment trial analysis. Methods in Ecology and Evolution, v. 11, n. 6, p. 783–789, 2020↩︎
O pacote ggthemes (https://mran.microsoft.com/snapshot/2015-04-01/web/packages/ggthemes/vignettes/ggthemes.html) pode ser utilizado para aumentar o leque de possibilidades.↩︎